

Abstract
How the CNS transforms visual information of object properties into motor commands for manipulation is not well understood. We designed novel apparatus and protocols in which human subjects had to learn manipulations in two different contexts. The first task involved manipulating a U-shaped object that can afford two actions by grasping different parts of the same object. The second task involved manipulating two L-shaped objects that were posed at different orientations. In both experiments, subjects learned the manipulation over consecutive trials in one context before switching to a different context. For both objects and tasks, the visual geometric cues were effective in eliciting anticipatory control with little error at the beginning of learning of the first context. However, subjects failed to use the visual information to the same extent when switching to the second context as sensorimotor memory built through eight consecutive repetitions in the first context exerted a strong interference on subjects' ability to use visual cues again when the context changed. A follow-up experiment where subjects were exposed to a pseudorandom sequence of context switches with the U-shaped object revealed that the interference caused by the preceding context persisted even when subjects switched context after only one trial. Our results suggest that learning generalization of dexterous manipulation is fundamentally limited by context-specific learning of motor actions and competition between vision-based motor planning and sensorimotor memory.
Introduction
Dexterous manipulation is a unique and critically important human behavior that relies on integrating cognition, visual information, and sensorimotor memory for planning hand–tool interactions. When starting to learn a manipulation task, inferring object properties through vision allows humans to anticipate task dynamics and appropriate motor commands for modulating digit forces and placement (Gordon et al., 1991; Lukos et al., 2008; Fu et al., 2010). However, large discrepancies may exist between visual cues and object physical properties, e.g., a visually symmetric shape with an asymmetric mass distribution (Salimi et al., 2003; Bursztyn and Flanagan, 2008; Zhang et al., 2010), an unknown mass associated with a virtual object (Ingram et al., 2011), or a large object that is lighter than its visual size may suggest (Flanagan and Beltzner, 2000). These discrepancies result in an erroneous initial visual estimation of task dynamics and large performance errors at the beginning of the learning process. Consequently, on later trials, subjects have to rely on sensorimotor memory of the experienced task dynamics to learn object manipulation rather than on these ineffective visual cues. This is because the information acquired through sensorimotor learning might be weighted more than vision, as the former is more reliable (Ernst and Banks, 2002; Säfström and Edin, 2004).
It has also been shown that this sensorimotor memory acquired through hand–object interactions is specific to the object orientation at which the manipulation was learned. Specifically, subjects fail to generalize learned manipulations to new ones following a 180° physical rotation of the object. Hence, subjects have to relearn the task in the new context (Salimi et al., 2003; Bursztyn and Flanagan, 2008; Zhang et al., 2010; Ingram et al., 2011). The question arises whether the physical rotation of the target object is the primary factor that prevents the generalization. Physical rotation of the object may force subjects to perform a mental rotation of the previously established sensorimotor memory (Ingram et al., 2010), similar to the mental rotation in visual object recognition, which is considered computationally challenging for the brain (Zacks, 2008). Alternatively, failure to generalize learned manipulation may be an intrinsic feature of the sensorimotor system not limited to tasks involving changes of object orientation. Here we demonstrate, through novel experimental designs, that the context-dependency of the inability to generalize learned manipulation is not limited to rotation of objects with ineffective visual cues. Specifically, even with visual geometric cues congruent with object dynamics, subjects fail to generalize learned manipulations when asked to manipulate the same object by grasping different parts of the object as well as when manipulating different objects. Furthermore, we discovered a surprising phenomenon: sensorimotor memory built in the preceding manipulation context, as well as through consecutive practice in the same context, can interfere with subjects' previous ability to effectively use visual cues when they start to learn manipulation in a new context, therefore preventing immediate learning generalization.
Materials and Methods
Participants
Forty-eight healthy right-handed subjects (22 females, 26 males; 18–28 years of age) participated in this study. All participants were naive to the purpose of the study and gave their informed consent according to the Declaration of Helsinki. The protocols were approved by the Office of Research Integrity and Assurance, Arizona State University. Subjects were divided into three groups (16 subjects in each group). Each subject group participated to one of three protocols: blocked U, blocked 2L, and random U.
Apparatus
All subjects were instructed to lift the designated object vertically with their right hand while preventing the object from tilting, i.e., “as if trying to prevent a cup full of water from spilling”. The three protocols differed based on the shape of the object used for the manipulation and trial sequences. We used two object shapes: U and L, both of which had a base (19 × 5 × 5 cm3, 375 g) made of white plastic. The U-shaped object had two vertical handles mounted on the two ends of the long side of the base; the L-shaped objects had only one vertical handle mounted on either left of right end of the base. All vertical handles (6.5 × 10 × 3 cm3, 275 g) were made of gray plastic and equipped with two hidden six-axis force–torque sensors (Nano-25; ATI Industrial Automation; Fig. 1A–C). The subjects were told and shown (without lifting the object) that the handles were rigidly attached to the base. The design of the handle enabled measurement of forces and torques applied by the digits. We computed the center of pressure at both vertical contact surfaces on the opposing sides of the handle and the net compensatory torque (see below) applied on the handle. Both U- and L-shaped objects provided visual geometrical cues that were congruent with the object's mechanical properties (mass, friction, and mass distribution). Object kinematics was measured using a motion tracking system (Impulse; PhaseSpace). Technical details of the sensors and force/torque data processing algorithms have been reported previously (Zhang et al., 2010; Fu et al., 2011).
Protocols
The objects were located 30 cm in front of the subjects. Subjects were asked to shift their body sideways to align their right shoulder with the designated handle of the object to ensure a comfortable grasp. On hearing a go signal, subjects reached to grasp and lift the object ∼5 cm above the table and then held it in a stationary position for ∼2 s. Subjects were required to grasp the specified handle with the tip of the thumb on the left contact surface and the tip of the index and middle fingers on the right contact surfaces of the handle (Fig. 1A), and to prevent the object from tilting (Fig. 1B,C). Subjects then replaced the object back to the table. All tasks required subjects to plan and generate torques in an anticipatory fashion to compensate the torque caused by asymmetrical mass distribution with respect to the hand (Fu et al., 2011).
Before the experiments started, the objects were visually presented to the subjects and they were allowed to touch the grip surface briefly to familiarize themselves with the friction but without lifting the object. All protocols contained 32 trials that consisted of two contexts, L and R. Subjects were instructed to perform the manipulation task in one of the contexts according to experimenter's instructions before each trial or blocks of trials. Within each protocol, 16 subjects were evenly divided into two groups to start with either L or R contexts. The intertrial and interblock resting times were ∼10 s. The three protocols are described below.
Blocked U protocol.
Subjects were presented with the U-shaped object that afforded two equal but opposite contexts, L and R, when lifted by grasping either the left or right handle, respectively (Fig. 1B). As subjects were asked to balance the object while lifting it, context L required subjects to produce a counterclockwise (CCW) compensatory torque of 550 Nmm whereas context R required a clockwise (CW) compensatory torque of 550 Nmm. The trial sequence was presented in a blocked fashion that required subjects to switch context after every eight consecutive trials in the same context (L to R, R to L; Fig. 1D).
Blocked 2L protocol.
Subjects were first presented with one of two L-shaped objects, both of which had a single vertical handle that afforded a single action. The two objects were identical except that one had the handle on the left (left L-shape) and the other had the handle on the right (right L-shape). Context L required subjects to lift the left L-shaped object and produce a CCW compensatory torque of 320 Nmm; context R required lifting the right L-shaped object and producing a CW compensatory torque of 320 Nmm. To ensure that subjects understood they were interacting with different objects, the left and right L-shaped objects were labeled “B” and “A,” respectively, with the label attached to the front of the handle (Fig. 1C). When the target object was presented (e.g., left L-shape), the other object (e.g., right L-shape) was occluded from view by a cardboard box. When subjects were asked to switch to the other object, they used both hands to lift the box and place it over the previously manipulated object. This procedure further ensured that subjects were aware that the upcoming trials were to be performed on a different object, while preventing the other object from acting as a distractor during grasping and lifting of the nearby object. The trial sequence was presented in a blocked fashion that required subjects to switch context after every eight consecutive trials in the same context (L to R, R to L; Fig. 1D).
Random U protocol.
Subjects were presented with the same U-shaped object used for the blocked U protocol (Fig. 1B). The trial sequence was designed to expose subjects to L and R contexts in a pseudorandom fashion for the first block of 16 trials, followed by two blocks of eight consecutive trials for each context (Fig. 1E). Subjects had to switch context after the first trial, then they had to switch contexts multiple times every one, two, or three trials before the last two blocks of trials. Each context was presented eight times in a pseudorandom sequence.
Data analysis
We used the compensatory torque (Tcom) subjects generated at object lift onset to quantify subjects' ability to anticipate manipulative forces. In our previous work, we validated the use of Tcom to quantify learning of high-level representations of manipulations independent of trial-to-trial variability of digit placement and forces engaged in the task (Fu et al., 2010, 2011). Note that Tcom at object lift onset is a direct measure of anticipatory control of manipulation as it is computed before the object is lifted. As such, Tcom on Trial 1 in all protocols is a measure of anticipatory control of manipulation based only on visual geometric cues. Tcom on the following trials is expected to be influenced by both visual geometric cues and sensorimotor memory acquired through manipulations performed on previous trials. Importantly, the discrepancy between the Tcom produced at lift onset and the torque required to perfectly prevent object roll (Ttask) positively correlates with the error in behavioral performance quantified as object peak roll (32 trials × 48 subjects = 1536 trials; r = 0.71, p < 0.001). We found that subjects never produced a Tcom in the wrong direction with respect to Ttask. Therefore, to simplify the statistical analysis, we used the absolute magnitude of Tcom (|Tcom|) despite the fact that the compensatory torques were exerted in opposite directions for the L and R context in each protocol.
Statistical analyses were designed to assess Tcom within-block learning, interblock interactions, and differences between protocols. The following statistics were used.
First, for each block of eight consecutive trials performed in the same context (all four blocks in blocked U and blocked 2L, and the last two blocks in random U), we performed two-way ANOVA using TRIAL as within-subject factor to examine whether the production of |Tcom| improved across eight trials and GROUP as between-subject factor to examine whether L and R contexts differed from each other (Fig. 1D,E).
Second, we performed two-way ANOVA using TRIAL as within-subject factor and GROUP as between-subject factor to compare |Tcom| in Trial 1 of Block 1 versus the first postswitch trials (Trial 9 in blocked U and blocked 2L; Trial 2 in random U), as well as potential differences between L and R contexts, respectively (Fig. 1D,E). This analysis determines whether sensorimotor memory built through performing the manipulation task in Context 1 affects the ability to use visual geometry cues at the beginning of Context 2. The rationale for this analysis is that the manipulation planning error (the difference between Ttask and Tcom) on the first trial could only be caused by visual estimation of object dynamics, whereas the error in the first postswitch trials could have been influenced by both sensorimotor memory built through practice during Block 1 and the new visual estimation of task dynamics.
Third, we performed two-way ANOVA using TRIAL as within-subject factor and GROUP as between-subject factor to determine whether |Tcom| produced in the first trials changed across Blocks 2, 3, and 4 for blocked U and blocked 2L. Note that at the beginning of Blocks 3 and 4, subjects would have acquired sensorimotor memory of manipulations of both Context 1 and Context 2 performed in Blocks 1 and 2 (Fig. 1D).
Fourth, we performed one-way multivariate ANOVA using GROUP as between-subject factor to examine whether starting with L or R handle caused subjects to produce |Tcom| differently in the first block of 16 random trials for random U (Fig. 1E).
Fifth, we performed two-way ANOVA using TRIAL as within-subject factor and GROUP as between-subject factor to determine whether |Tcom| changed across eight postswitch trials in the first block of 16 random trials for random U (Fig. 1E).
Sixth, we performed two-way ANOVA using TRIAL as within-subject factor and GROUP as between-subject factor to determine whether |Tcom| changed across trials following the postswitch trials in random trials (Trials 3, 5, 9, 12, 14, and 16) as well as in blocked trials (Trials 18–24) for random U (Fig. 1E).
Finally, we performed two-way ANOVA using PROTOCOL and GROUP as between-subject factor to examine whether the extent of exposure to one context before switching to a different context influences the |Tcom| produced in the first postswitch trial (Trial 9 in blocked U vs Trial 2 in random U), as well as to compare the last postswitch trial (Trial 25) in both protocols (Fig. 1D,E).
Results
We did not find any significant difference between the subject group that started with the R versus the L context in any of the statistical analyses for all three protocols. Therefore, we report the results obtained by pooling data from group R and L and define the first context subjects started with as Context 1 and the subsequent context as Context 2, regardless of whether they started with context L or R (Fig. 1D,E).

Experimental apparatus and protocol. A, Design of one-handled instrumente with force/torque sensors. B, Two opposite actions afforded by the U-shaped object when grasped by its left and right handles (blocked U and random U protocols). C, Two opposite actions afforded by two L-shaped objects depending on the location of the handle relative to the base (blocked 2L protocol). D, Trial sequences for the two blocked protocols where subjects switched contexts after each block of eight consecutive trials of a given context. E, Trial sequences for the random U protocol where task context switched in a pseudorandom fashion throughout the first 16 trials, followed by two blocks of eight consecutive trials of each context.
Blocked U protocol: learning and generalization
The effectiveness of visual cues in eliciting manipulative actions was validated in the first block of trials in which subjects produced Tcom very close to Ttask on the first trial (|Tcom| = 429.1 ± 34.7 Nmm, mean ± SE; |Ttask| = 550 Nmm). This result indicates that subjects were able to use visual cues of object geometry to infer the direction and magnitude of the torque they needed to counteract using Tcom. This was further confirmed by the fact that implicit knowledge of object mass distribution acquired through subsequent trials did not improve performance (no significant main effect of TRIAL, p = 0.21; Fig. 2A). Therefore, before lifting the object for the first time, subjects were able to use only visual geometric cues about object mass distribution and prior knowledge of material properties to predict the dynamics of the manipulation task. However, despite the almost perfect performance afforded by visual estimation, subjects failed to use it for planning a different manipulation when asked to switch to the other handle after Block 1. This counterintuitive result was revealed by significantly smaller Tcom in the first trial of Block 2 (|Tcom| = 198.1 ± 30.9 Nmm) versus the first trial of Block 1 (significant main effect of TRIAL, F(1,14) = 20.39; p < 0.001; Fig. 2B), as well as a significant trial-to-trial learning in Block 2 (significant TRIAL effect, F(7,98) = 25.25, p < 0.001). This suggests that, after changing the part of the (same) object grasped to perform the manipulation, sensorimotor memory not only prevented generalization across different contexts, but also produced interference on the ability to use visual estimation again for grasp planning. Remarkably, even though subjects had acquired sensorimotor memory of both manipulations at the beginning of Block 3 and Block 4, performance error when switching between two contexts persisted, and both blocks showed significant relearning (Blocks 3 and 4: significant main effect of TRIAL; F(7,98) = 29.54 and 10.04, respectively; both p < 0.001; Fig. 2A). The interference was weakened by accumulating more practice of both manipulations, as shown by a significant reduction of error on the first trial across the last three blocks (significant main effect of TRIAL; F(2,28) = 11.78, p < 0.001; Fig. 2B). These results suggest that context-dependent learning interferes with the ability to use visual information each time that the context changes despite strong explicit (visual) cues about object dynamics. One may question whether this interference is object-dependent, that is, whether the inability to generalize one learned manipulation in one context to another context is due to the fact that subjects were always interacting with the same object. If so, learning a manipulation with an object should not produce interference when performing a different manipulation with another object. To examine this issue, we tested the second protocol, blocked 2L, in which subjects had the same blocked trial sequence (switching context every eight trials), but now the two contexts were associated with two different objects.

Experimental results of blocked U protocol. A, Directional compensatory torque (Tcom) at object lift onset (top) and absolute peak object roll (bottom) as a function of trial. Data are mean values averaged across all subjects and SEM (midline and height of the green squares, respectively, for Tcom). The red and blue backgrounds indicate Context 1 and Context 2, respectively. *Significant main effect of trial. B, Absolute Tcom magnitude (|Tcom|) produced in the first trial (T1) and on all postswitch trials (S1, S2, and S3; see Fig. 1). Data are mean values averaged across all subjects and vertical lines denote SEM. *Significant difference at p < 0.01. Horizontal dashed lines in A and B denote task torque magnitude.
Blocked 2L protocol: learning and generalization
In Block 1, the visual cues were as efficient as the blocked U experiment for predicting the direction of the torque. However, subjects underestimated the torque magnitude, as performance was characterized by a moderate error (|Tcom| = 174.8 ± 14.7 Nmm; |Ttask| = 320 Nmm) and a statistically significant learning curve (significant main effect of TRIAL, F(7,98) = 10.77, p < 0.001; Fig. 3A). However, the interference caused by the sensorimotor memory of the first manipulation was again found as the |Tcom| in Trial 1 of Block 2 (83.9 ± 16.6 Nmm) was significantly smaller than that of Trial 1 of Block 1 (significant main effect of TRIAL, F(1,14) = 12.8, p = 0.003; Fig. 3B). This result is consistent with the above result from the U-shaped object. Importantly, this finding indicates that the interference produced by sensorimotor memory of a manipulation on planning a different manipulation is not limited to manipulations performed with the same object (U-shape) as it also occurs when switching task contexts, i.e., changing the target object. Lastly, similar to the blocked U experiment, with further practice, the interference due to switching task contexts decreased, as shown by the increase in |Tcom| across Trial 1 of Blocks 2, 3, and 4 (significant main effect of TRIAL; F(2,28) = 32.50, p < 0.001; Fig. 3B).

Experimental results of blocked 2L. Data from the blocked 2L protocol are shown in the same format as Figure 2. A, Directional compensatory torque (Tcom) at object lift onset (top) and absolute peak object roll (bottom) as a function of trial. B, Absolute Tcom magnitude (|Tcom|) produced in the first trial (T1) and on all postswitch trials (S1, S2, and S3).
Random U protocol: learning and generalization
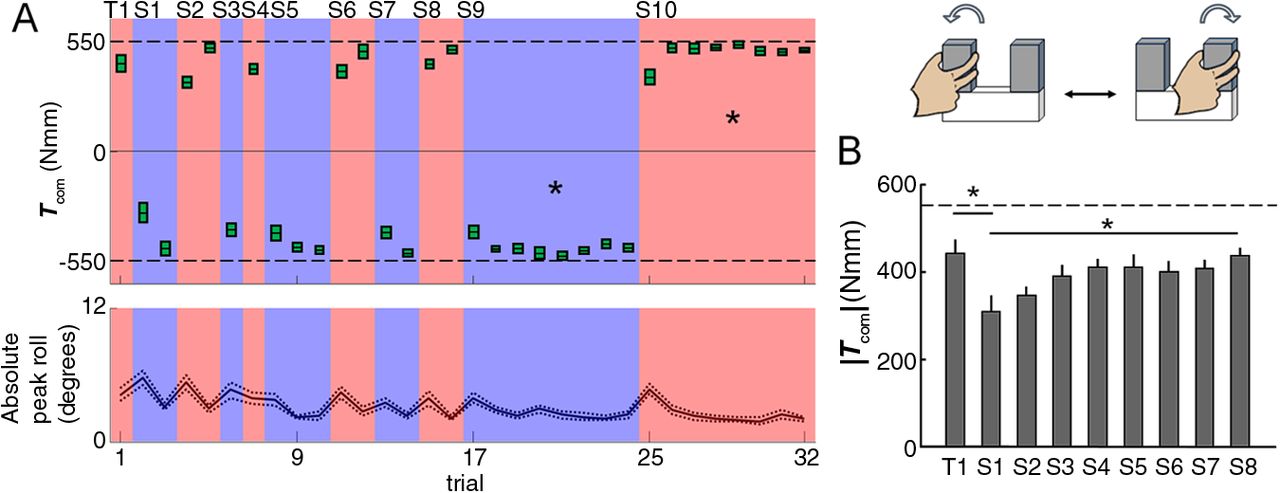
The first two protocols indicate that exposure to manipulation in one context over consecutive trials interferes with the ability to use visual information to anticipate object dynamics when switching context regardless of whether two contexts are afforded by the same or different objects. Therefore, the question arises about the neural mechanism that might underlie this surprising yet general phenomenon. The third protocol, random U, was designed to further our understanding about this novel interference by using a random context sequence using the U-shaped object. The rationale of this design was to prevent subjects from being exposed to the same context consecutively over many trials (Fig. 1E) and therefore determine whether the above-described interference can occur after minimal exposure (1 to 3 trials) to a given manipulation context. Consistent with the results of the blocked U condition, subjects made very little error on the first trial (|Tcom| = 440.1 ± 32.2 Nmm; |Ttask| = 550 Nmm) when using only visual estimation of object dynamics (Fig. 4A). However, when subjects switched to Context 2 immediately after Trial 1, without further practice in Context 1, they produced a significantly smaller |Tcom| than on the previous trial (significant main effect of TRIAL; F(1,14) = 13.11, p = 0.003; Fig. 4B). This indicates that exposure to just one trial to Context 1 creates an interference on manipulation planning on the postswitch trial. This interference was significantly smaller than the interference caused by eight consecutive trials in the blocked U condition, as indicated by the significantly larger |Tcom| in the first switch for the random U condition (significant main effect of PROTOCOL; F(3,28) = 5.28, p = 0.029; Fig. 5). Similar to the blocked U condition, subjects tested in the random U protocol showed |Tcom| improvement on postswitch trials across multiple switches (significant main effect of TRIAL; F(7,98) = 3.32, p = 0.003; Fig. 4B).

Experimental results using protocol random U. Data from the random U protocol are shown in the same format as Figure 2. Note that this protocol is characterized by 10 context switches occurring after a variable number of trials with a given context [first 16 trials (S1–S8), one context switch at the beginning of the first series of 8 consecutive trials (S9), and one last context switch after eight consecutive trials with a given context (S10)]. A, Directional compensatory torque (Tcom) at object lift onset (top) and absolute peak object roll (bottom) as a function of trial. B, Absolute Tcom magnitude (|Tcom|) produced in the first trial (T1) and on all eight postswitch trials (S1–S8).

Comparison of results from random U and blocked U protocols. The figure shows the absolute magnitude of the compensatory torque (|Tcom|) exerted on the first and last context switch for the blocked U and random U protocols. Data are mean values averaged across all subjects and vertical lines denote SEM. The horizontal dashed line denotes task torque magnitude. *Significant difference, p < 0.05.
Subjects performed the manipulation on each handle eight times during the first 16 trials in both blocked U (Fig. 2A) and random U (Fig. 4A) conditions. For the random U condition, we found no significant differences in |Tcom| across the trials that followed each postswitch trial (Trials 3, 5, 9, 12, 14, and 16; p = 0.78). t tests revealed that the average |Tcom| measured for these trials were not significantly different from the last six trials of either Block 1 or Block 2 from the blocked U condition (Trials 3–8 or Trials 10–16, respectively; p > 0.05). This indicates that subjects' performance following the context switch trial has recovered from the initial interference to a level similar to that observed through consecutive trials in the blocked U condition. Lastly, after the first 16 trials, subjects in both blocked and random U conditions performed another eight consecutive trials (Trials 17–24). The |Tcom| in the last postswitch trial (Trial 25) from these two experimental conditions was not significantly different (Fig. 5) and subjects in the random U condition showed significant relearning (significant main effect of TRIAL; F(7,98) = 12.22, p < 0.001; Fig. 4A), as was also found for the blocked U condition.
Discussion
Context-dependent learning of manipulation with visual geometric cues
Unlike previous work using objects with visual cues that are incongruent with their dynamics, we demonstrated the powerful effect of visual geometric cues on the initialization of the internal model of a new manipulation task (Trial 1, all experimental conditions). It has been shown that humans can identify the center of mass of multiple separate or combined rigid bodies (Baud-Bovy and Soechting, 2001; Liby and Friedenberg, 2010). Our results indicate that this estimation can be used in the process of visuomotor transformation to generate motor commands for manipulative actions. Specifically, geometric cue-based anticipatory control was equally efficient at predicting the direction of the task in both blocked U and random U protocols. However, the asymmetrical shape (L-shape) appears to be less effective for estimating torque magnitude than the symmetrical one (U-shape), although it is still effective for predicting torque directions. This result is consistent with previous work showing that subjects make larger errors when estimating the position of net center of mass of a triangular than a rectangular shape (Liby and Friedenberg, 2010).
Despite the effectiveness of visual cues, we found that failure of generalizing learned manipulation across different contexts (different parts of the same object and different objects) appears to be a general phenomenon encountered when the sensorimotor system faces the challenge of switching between two contexts that require opposite manipulative actions (e.g., CW vs CCW). This is demonstrated by the large error subjects made when switching to a new context for the first time. As our results were obtained without changing the orientation of the object, the present findings of context-dependency of learning generalization are consistent with, and extend beyond, the orientation-dependency of generalization of learned manipulations (Salimi et al., 2003; Bursztyn and Flanagan, 2008; Zhang et al., 2010; Ingram et al., 2011).
Sensorimotor experience interferes with the ability of using visual information
The most important and novel finding from our study is that the effectiveness of visually based grasp planning was significantly reduced by previous exposure to an opposite manipulation in a different context. While visual cues were still effective in eliciting the prediction of task torque direction, their effectiveness for predicting task torque magnitude was interfered by the previously learned action. Specifically, given the same context (R or L), the errors subjects made in anticipatory control were significantly larger when they had operated in a context that required opposite manipulative actions than when they only had visual information available (Figs. 2B, 3B, 4B). In addition, longer consecutive exposure to one context induced more interference than single-trial exposure (Fig. 5). To the best of our knowledge, our result is the first evidence that sensorimotor experience interferes with the previously demonstrated ability to transform visual input of object geometry into motor commands for manipulation planning. Interference has been demonstrated as a reduction of learning rate in one context preceded by an opposite context using force fields (Sing and Smith, 2010) as well as visuomotor rotations (Krakauer et al., 2005). However, due to the presence of strong visual cues, our tasks are different because they are characterized by familiar dynamics, hence by a much faster learning rate than adaptation to force fields and visuomotor rotations (Ingram et al., 2011). Therefore, in our study, the interference induced by previously learned context was revealed by a reduction of vision-based anticipatory control rather than a reduction in learning rate.
Even though the two contexts we studied require opposite digit force coordination patterns to produce compensatory torques in opposite directions, the present interference is unlikely to have occurred due to a bias at the level of individual digits or muscle groups. It has been shown that subjects made no performance error when switching to an opposite digit force coordination pattern following a 180° hand rotation (Bursztyn and Flanagan, 2008). It has also been shown that subjects were able to redistribute digit forces and positions when switching across grip types to lift the same object (Fu et al., 2011). These findings suggest that manipulation can be learned in a digit-independent fashion. Specifically, opposite actions at the digit level alone do not appear to interfere with planning and execution of subsequent manipulations when the task dynamics (the direction and magnitude of the task torque) is invariant with respect to the subjects. Therefore, the interference from exposure to one preceding context found in our study is more likely to have occurred at the task level during planning manipulation, such that switching between two opposite contexts caused significant conflict in initialization of the task goal.
It has been recently shown that motor learning may involve parallel processes including error-based update of internal models (Haruno et al., 2001) and model free mechanisms such as use-dependent plasticity (Diedrichsen et al., 2010). Using visuomotor rotation tasks, Huang and colleagues (2011) showed that fast adaptation of an internal model channels movement toward successful error reduction, and repetition of the newly adapted movement slowly induces directional biases toward the repeated movement through use-dependent plasticity even when subjects made little performance error. If we assume the sensorimotor system learns and controls object manipulation in a similar fashion as reaching movements, we could speculate that the interference in our data arises from both model-based and model-free learning processes. Specifically, the interference induced by one trial exposure to manipulation may be caused by the updated internal model of the first context, which competes with the visual-based initialization of the internal model for the second context, whereas the greater interference induced by consecutive movement repetitions may be caused by the additional involvement of use-dependent plasticity. Note, however, that object manipulation is characterized by a very different adaptation time scale than reaching movements. Specifically, a manipulation can be learned within a few trials because only parameterization, as opposed to structural learning, is required for the familiar dynamics encountered in object-manipulation tasks (Ingram et al., 2011).
Additional evidence for use-dependent plasticity comes from the fact that subjects in both random and blocked conditions made similar errors on the last switch (Trial 25; Figs. 2B, 3B, 4B). This suggests that eight repetitions of same context still caused interference on the subsequent context even when both contexts had been learned by the end of the first 16 trials. Lastly, the fact that interference persisted but was reduced after multiple context switches suggests that subjects might have used contextual cues (i.e., associating a handle to a previously experienced manipulation) to switch to the correct internal model (Osu et al., 2004; Cothros et al., 2009).
Possible neural networks underlying the context-dependent interference
Our data suggest the existence of complex interactions and weight tuning between sensorimotor experience and visual estimation of object dynamics for generating precise motor commands, which can potentially lead to a competition between these processes and therefore suboptimal performance. Although it is not clear where the interaction between internal model, online visuomotor control, and model-free learning occurs in the brain, extensive research has shown that neural circuits underlying skilled manipulation involve a large network that transforms visual attributes of the object into goal-directed motor commands (Davare et al., 2011). The key regions consist of the anterior intraparietal area (AIP), ventral premotor (PMv), and primary motor cortex (M1). Experimental evidence from transcranial magnetic stimulation studies have shown that projections from visual cortex to AIP can affect M1–PMv functional connectivity (Davare et al., 2010), whereas PMv would be involved in facilitating M1 activity in a grasp-specific fashion (Davare et al., 2008). Furthermore, before visual information is available to the AIP–PMV–M1 circuitry, sensorimotor memory stored in the corticospinal system (M1) and/or cerebellum has the greatest influence on motor planning (Loh et al., 2010). It has also been suggested that changes in motor cortex induced by prior motor practice underlies use-dependent plasticity (Verstynen and Sabes, 2011). Our data show that the influence of sensorimotor experience can be very strong and could not be fully suppressed by visual input. Weight tuning of sensorimotor memory and vision could be beneficial for action planning in stochastic environments in which the task goal of the upcoming context is difficult to predict (Verstynen and Sabes, 2011). At the same time, however, in a deterministic environment, the sensorimotor system is somewhat limited in its ability to switch between contexts without performance degradation.
Conclusions
Our findings suggest that context-dependency is a generic feature in learning and generalization of dexterous manipulation: subjects primarily learn the action rather than the actual physical properties of the tool. Furthermore, we demonstrate that, although visual geometry cues can be very powerful for anticipatory control of dexterous manipulation, their contribution to motor planning is significantly inhibited by sensorimotor memory acquired through as little as one trial practice, therefore inducing interference. This interference may play an important role in preventing generalization of learned manipulation across different contexts. The present sensorimotor–visual interference provides novel insight into visuomotor transformations for skilled manipulation and an experimental framework for characterizing the neural circuitry responsible for linking perception and action.
Footnotes
This work was supported by National Science Foundation (NSF) Collaborative Research Grant IIS 0904504. The contents are solely the responsibility of the authors and do not necessarily represent the official views of NSF. We thank the Neural Control of Movement Laboratory members for their comments on the experimental design. We also thank Dr. Stephen Helms Tillery, Dr. Christopher Buneo, and Dr. Andrew Gordon for comments on an earlier version of the manuscript.
- Correspondence should be addressed to Dr. Marco Santello, School of Biological and Health Systems Engineering, 501 East Tyler Mall, ECG Building, Suite 334, Arizona State University, Tempe, AZ 85287-9709. marco.santello{at}asu.edu





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}