

Abstract
The ability of an animal to detect weak sensory signals is limited, in part, by statistical fluctuations in the spike activity of sensory afferent nerve fibers. In weakly electric fish, probability coding (P-type) electrosensory afferents encode amplitude modulations of the fish's self-generated electric field and provide information necessary for electrolocation. This study characterizes the statistical properties of baseline spike activity in P-type afferents of the brown ghost knifefish, Apteronotus leptorhynchus. Short-term variability, as measured by the interspike interval (ISI) distribution, is moderately high with a mean ISI coefficient of variation of 44%. Analysis of spike train variability on longer time scales, however, reveals a remarkable degree of regularity. The regularizing effect is maximal for time scales on the order of a few hundred milliseconds, which matches functionally relevant time scales for natural behaviors such as prey detection. Using high-order interval analysis, count analysis, and Markov-order analysis we demonstrate that the observed regularization is associated with memory effects in the ISI sequence which arise from an underlying nonrenewal process. In most cases, a Markov process of at least fourth-order was required to adequately describe the dependencies. Using an ideal observer paradigm, we illustrate how regularization of the spike train can significantly improve detection performance for weak signals. This study emphasizes the importance of characterizing spike train variability on multiple time scales, particularly when considering limits on the detectability of weak sensory signals.
- electrosensory afferent
- electrolocation
- interspike interval analysis
- Markov process
- spike train variability
- weak signal detection
Survival in an animal's natural environment is dependent on the ability to detect behaviorally relevant stimuli, such as those caused by predators and prey. Being able to reliably and efficiently detect such signals at weak levels confers a competitive advantage. Thus many sensory systems, including the electrosensory system discussed here, have presumably experienced selective pressures over the course of evolution to improve detection performance for weak sensory signals.
The decision of whether or not a stimulus is present must ultimately be based on a change in the spike activity of primary afferent nerve fibers. In many cases, this change must be detected in the presence of ongoing spontaneous activity. Intuitively, a subtle change in spike activity caused by a weak external signal should be easier to detect when the baseline activity is regular and predictable than when it is irregular and subject to random fluctuations. To understand the limits on signal detection performance, it is thus important to characterize the variability of baseline activity in primary afferent spike trains.
A common approach for characterizing spike train variability is by analysis of the first-order interspike interval (ISI) distribution (Hagiwara, 1954; Moore et al., 1966;Ratliff et al., 1968; Gabbiani and Koch, 1998). The coefficient of variation (the SD divided by the mean) of the ISI distribution provides a convenient measure of the variability in the arrival time between successive spikes. It is important to realize, however, that the first-order ISI distribution only provides information about short-term variability on time scales comparable to the mean ISI. Long-term variability, over time periods containing multiple spikes, must be measured using other techniques, such as analysis of higher-order interval distributions (Rodieck et al., 1962; Moore et al., 1966) or spike count distributions (Barlow and Levick, 1969a,b; Teich and Khanna, 1985).
Measurements of long-term variability for primary afferent spike trains are not commonly encountered in the literature. These measures would indeed be redundant if afferent spike activity could be adequately modeled as a renewal process. For a renewal process, successive intervals in the ISI sequence are independent and identically distributed (Cox, 1962) and therefore, higher-order interval and count distributions can be derived knowing only the first-order ISI distribution. Thus, variability on all time scales can be computed. However, when spike activity arises from a nonrenewal process there will be correlations and history-dependent effects in the ISI sequence. In such cases, the first-order ISI distribution does not provide sufficient information to predict long-term spike train variability or to set limits on signal detection performance.
In this paper, we analyze the variability of baseline spike activity recorded from P-type (probability coding) electrosensory afferent fibers in the weakly electric fish Apteronotus leptorhynchus(brown ghost knife fish). Objects near the fish that differ in impedance from the surrounding water modulate the self-generated electric field because of the fish's electric organ discharge (EOD). These modulations provide sensory cues that allow the fish to hunt and navigate in the dark using electrolocation (Rasnow, 1996) (for review, see Bullock and Heiligenberg, 1986). P-type afferents respond to the strength of amplitude modulations (AMs) by increasing or decreasing their probability of firing (Scheich et al., 1973; Bastian, 1981; for review, see Zakon, 1986). Their AM response characteristics have been well studied (Hagiwara et al., 1965; Scheich et al., 1973; Hopkins, 1976; Bastian, 1981; Shumway, 1989; Wessel et al., 1996; Xu et al., 1996; Nelson et al., 1997), but variability of baseline spike activity has not been fully characterized.
Infrared video recordings of prey capture behavior inApteronotus performed in our laboratory have been used to estimate the behavioral threshold for detecting small prey (Daphnia magna, 2–3 mm in length) in the dark. At the time of detection, we estimate that the prey gives rise to an AM signal that transiently changes the firing probability of P-type afferents by only ∼1% (Nelson and MacIver, 1999). In this study we show that P-type afferent spike trains are irregular as judged by the first-order ISI distribution but that there is an underlying nonrenewal process that serves to make the spike train more regular over longer time intervals. In an ideal observer framework (Green and Swets, 1966) this regularity effectively reduces the detection threshold for weak stimuli, such as those caused by small prey.
MATERIALS AND METHODS
Electrophysiology
Extracellular recordings were made from isolated P-type afferent fibers of weakly electric fish Apteronotus leptorhynchus.Surgical and nerve recording procedures used here are identical to those described in an earlier study (Xu et al., 1996). Briefly, fish were anesthetized in 100 ppm tricaine methanesulfonate (MS-222; Sigma, St. Louis, MO) and immobilized with an intramuscular injection of 3 μl 10% gallamine triethiodide (Flaxedil; Sigma). P-type afferent fiber activity was recorded from the posterior branch of the left anterior lateral line nerve (pALLN), which innervates trunk electroreceptors. Recordings were made in the presence of the EOD of the fish with no other stimulus present. We refer to activity under these conditions as “baseline” activity, in contrast to spontaneous activity that would be obtained if the EOD were silenced. Action potentials were recorded from individual pALLN fibers with glass microelectrodes (impedance of 10–30 MΩ) filled with 3 mKCl solution. Neural activity and EOD waveforms were digitized at 17 kHz and stored for offline analysis. Spike events in the nerve recording were identified by a threshold criteria and time-stamped with a resolution of 60 μsec. All data analysis was performed on Sun workstations using custom software and the MATLAB programming environment (The MathWorks).
Spike train representation
Apteronotus leptorhynchus has a continuous quasi-sinusoidal EOD waveform with a fundamental frequency f that ranges from 750 to 1000 Hz depending on the individual. P-type units fire at most once per EOD cycle and randomly skip cycles between successive spikes. On average, a typical unit fires on about one-third of the EOD cycles. This ratio is referred to as the per-cycle probability of firing p. In the presence of a stimulus, the per-cycle probability is modulated by stimulus intensity, and hence P units are called probability coders.
When spike times are sampled at intervals smaller than the EOD period, the timing of spikes within the cycle can be observed. This is illustrated in the ISI histogram shown in Figure1A. The peaks of the ISI distribution are separated by one EOD period. The width of each peak reflects the variability in firing phase within the EOD cycle. In subsequent analyses in this paper, we only keep information about the occurrence of a spike in an EOD cycle and discard information about the phase within the cycle. That is, we resample the spike train at the EOD frequency f. The effect of this resampling is seen in Figure1C, which is the discrete time ISI histogram for the fiber shown in Figure 1A. Time is measured in EOD cycles and hence, ISIs assume only integer values j ≥ 1, where j is the number of cycles to the next spike. For the remainder of this work, we only consider discrete-time spike trains sampled at the EOD rate.

Interval histograms of a P-type primary afferent fiber from the weakly electric fish Apteronotus leptorhynchus showing continuous-time (A, B) and discrete-time (C, D) representations.A, ISI histogram. Abscissa is multiples of EOD period (EOD frequency, f = 762 Hz). B, Joint distribution of adjacent intervals (joint interval histogram). Abscissa and ordinate are the i th and (i + 1) th ISIs in EOD periods, respectively, with symbol sizes proportional to probability of occurrence. Bin width is 180 μsec in A andB. Resampling the spike train at the EOD rate restricts the interspike intervals to integer values as shown in C (ISI histogram) and D (joint interval histogram). This afferent had a mean ISI of 2.9 EOD cycles and coefficient of variation (CVI(1)) of 0.47. Subsequent analysis in this paper is restricted to the discrete-time representation, in which spike trains are sampled at the EOD rate.
The resampled spike train is a realization of a discrete time stochastic process x(i) where i ≥ 1 is the EOD cycle number. Furthermore, x(i) = 1 if there is a spike in cycle i and is zero otherwise. The mean per-cycle firing probability is given by p = n/T where n = ∑i=1T x(i) is the total number of spikes observed in a record of duration T EOD cycles. The stochastic process x(i) can be characterized in terms of the statistical properties of the time intervals between spikes (interval analysis) or by the statistical properties of spike counts in time windows of fixed durations (count analysis) (Cox and Lewis, 1966).
Interval sequences and distributions of order k
Let ti represent the EOD period number in which the i th spike occurs. We set the time origin to be such that t1 = 1. Interval sequences of order k are defined as (Rodieck et al., 1962;Moore et al., 1966)
 Equation 1where n is the total number of spikes. The sequence Sk is a discrete-time stochastic process of strictly positive integers. The first-order interval sequence S1(i) = ti+1 − ti is the sequence of ISIs, S2(i) is the sequence of times between every second spike, etc. Let Ik be the normalized k th order interval histogram (IH) constructed from Sk. Then Ik(j) is the probability of observing an interval of length j in the sequence Sk. We denote the mean and variance of Ik by
Equation 1where n is the total number of spikes. The sequence Sk is a discrete-time stochastic process of strictly positive integers. The first-order interval sequence S1(i) = ti+1 − ti is the sequence of ISIs, S2(i) is the sequence of times between every second spike, etc. Let Ik be the normalized k th order interval histogram (IH) constructed from Sk. Then Ik(j) is the probability of observing an interval of length j in the sequence Sk. We denote the mean and variance of Ik by
 k and Var (Ik), respectively. In this paper, interval sequences and IHs were calculated for orders k up to 4096. In the neurophysiology literature, I1is used extensively and is referred to as the ISI distribution. The shape and statistical properties (mean and variance) of the ISI distribution are often used to characterize firing patterns and variability of spike timing. However, the ISI provides a characterization of spike variability only on time scales comparable to the mean ISI. Higher-order interval distributions provide information about variability over longer time scales and about dependencies in the ISI sequence.
k and Var (Ik), respectively. In this paper, interval sequences and IHs were calculated for orders k up to 4096. In the neurophysiology literature, I1is used extensively and is referred to as the ISI distribution. The shape and statistical properties (mean and variance) of the ISI distribution are often used to characterize firing patterns and variability of spike timing. However, the ISI provides a characterization of spike variability only on time scales comparable to the mean ISI. Higher-order interval distributions provide information about variability over longer time scales and about dependencies in the ISI sequence.
Dependency of an interval on the immediately preceding interval was analyzed using the joint interval histogram I(j1, j2), which reflects the probability of observing an ISI of length j1 followed by an ISI of length j2 (Rodieck et al., 1962). The joint interval histogram is constructed from the sequence S1 by binning all overlapping tuples (S1(i), S1(i + 1)), where 1 ≤ i ≤ n − 1. Figure 1, B andD, shows plots of the joint interval histogram corresponding to the sampling resolutions of Figures 1A and C, respectively.
Count distributions
An alternate analysis of spike train variability can be made using spike count distributions (Barlow and Levick, 1969a,b;Teich and Khanna, 1985). Proceeding as for interval analysis, count statistics were obtained from two measures: count sequences and count histograms. Let T be the number of EOD periods in which a count is to be performed. Then we define the count sequence NT by counting the number of spikes occurring in blocks of T contiguous EOD cycles. This can be expressed as:
 Equation 2where i refers to the block number in the sequence and n is the total number of recorded spikes. The normalized count histogram CT was also calculated from NT, so that CT(m) is the probability of obtaining m spikes in a count window of duration T EOD cycles. The mean and variance of CT are denoted by
Equation 2where i refers to the block number in the sequence and n is the total number of recorded spikes. The normalized count histogram CT was also calculated from NT, so that CT(m) is the probability of obtaining m spikes in a count window of duration T EOD cycles. The mean and variance of CT are denoted by
 T and Var (CT), respectively. Count sequences and histograms were calculated for T values ranging from 20 to as many as 50,000 EOD cycles, depending on data availability and subject to a minimum of 10 counting blocks.
T and Var (CT), respectively. Count sequences and histograms were calculated for T values ranging from 20 to as many as 50,000 EOD cycles, depending on data availability and subject to a minimum of 10 counting blocks.
Spike train models
To gain an understanding of the process that generates the observed spike train data x(i), we created surrogate spike trains using three model systems that reproduce certain statistical features of the afferent data.
Binomially generated spike train (B). The classic description of a P-type afferent is that it is a “probability coder.” Namely, the afferent fires irregularly with a per-cycle probability p that is constant under baseline conditions, but is subject to modulation in the presence of external stimuli. Thus, the simplest model of P-unit baseline activity is a process that emits a spike in any given EOD cycle with constant probability p independent of previous history. In a continuous-time framework, a constant firing probability per unit time gives rise to a homogeneous Poisson process, which frequently serves as a basis for models of spontaneous activity in neural spike trains (Tuckwell, 1988). In the discrete-time framework considered here, a constant firing probability per time step (one EOD cycle) gives rise to a binomial process. Whereas the Poisson process has exponentially distributed ISIs and Poisson-distributed spike counts, the binomial process has geometrically distributed ISIs and binomially distributed counts (see Eqs. 10 and 12, Appendix A). Surrogate binomial spike trains B were generated by shuffling the observed spike sequence x(i) to remove all dependencies between adjacent EOD periods. Per-cycle firing probability p remains unchanged because shuffling preserves the total number of spikes and EOD periods.
Zeroth-order Markov process (M0). The binomially generated spike train matches p but does not guarantee that the interval distributions will be the same as the data. A surrogate spike train that preserves p as well as the ISI distribution I1, can be generated by randomly shuffling the ISI sequence S1, rather than shuffling the spike train x. This preserves the total number of intervals and the distribution of intervals but removes dependencies between neighboring intervals in the sequence (Longtin and Racicot, 1997a). For reasons discussed below, this process will be referred to as M0, indicating that it is a zeroth-order Markov process.
First-order Markov process (M1). Interval distributions of experimentally observed spike trains often exhibit dependencies on prior activity and are thus nonrenewal (Kuffler et al., 1957; Werner and Mountcastle, 1963;Teich et al., 1990; Lowen and Teich, 1992). Surrogate spike trains that preserved dependencies between adjacent ISIs were constructed from the afferent data. First, all adjacent pairs of intervals (ji, ji+1) were tabulated and sorted into groups, each having identical first element. A group, say with first element ja, was selected at random, and a tuple was drawn, say (ja, jb). The next tuple was drawn at random from the group which had first element jb. If this tuple was (jb, jc), the resultant of the two draws was the triplet (ja, jb, jc). All draws were made without replacement. Continuing in this manner, an ISI sequence was constructed that had joint probability I(j1, j2) that matched the data. As discussed below, the resulting sequence is a first-order Markov process and will be denoted by M1.
The binomial (B) and zeroth-order Markov (M0) processes are examples of renewal processes (Cox, 1962) because successive intervals in the ISI sequence S1 are independent and identically distributed. The first-order Markov process (M1) is a nonrenewal process because intervals are not independent. Appendix summarizes some results for renewal processes.
Measures of variability
A common measure of spike train variability is the coefficient of variation of the ISI distribution CVI, defined as the SD of the ISI distribution divided by its mean. Because it is a dimensionless quantity, it can be used for comparing the variability of two distributions even when they differ in their means. To measure variability of ISIs on different time scales, we also computed CVI for higher order interval distributions. The coefficient of variation CVI(k) for the k th order interval distribution Ikis:
 Equation 3
Equation 3
Another useful measure is the variance-to-mean ratio of Ik, denoted FI(k):
 Equation 4
Equation 4
Although this measure has the disadvantage that it is not dimensionless, it has the useful property that for all orders k, it is constant for a renewal process (see Appendix ). For any process that is more regular than a renewal process, the variance-to-mean ratio decreases with increasing k.
Analogous to the measures of variability for interval sequences, it is possible to define similar measures for count sequences NT. Proceeding as above, the coefficient of variation CVC(T) for the count distribution CT(i) is defined as:
 Equation 5
Equation 5
For spike count distributions, the variance-to-mean ratio is called the Fano factor (Fano, 1947). It is denoted FC(T) and defined as:
 Equation 6
Equation 6
Correlation analysis
History-dependent effects were analyzed by considering the serial correlation coefficient (SCC) ρl of the first-order sequence S1, where l is the lag in terms of the number of intervening intervals. The ρl were computed from:
 Equation 7where j1, … , jMis a sequence of M consecutive ISIs that can start anywhere in the ISI sequence S1. The values of ρl range from +1 (perfect correlation) to −1 (perfect anti-correlation), and ρl = 0 when intervals are uncorrelated.
Equation 7where j1, … , jMis a sequence of M consecutive ISIs that can start anywhere in the ISI sequence S1. The values of ρl range from +1 (perfect correlation) to −1 (perfect anti-correlation), and ρl = 0 when intervals are uncorrelated.
To determine if the ρl were significantly different from zero, the sequence S1 was divided into nonoverlapping blocks each having M = 1000 elements S1(i), … , S1(i + M − 1), and the ρl were determined for each block. The sequence S1 was then shuffled to eliminate dependencies between intervals, if any, and the ρl were again evaluated for the same number of blocks M. For each lag, the unshuffled and shuffled SCCs were tested under the null hypothesis that the two populations were identical. A Wilcoxon rank sum test was used to test the hypothesis at a significance level of p = 0.01.
Analysis of Markov order
SCCs do not completely characterize dependencies between ISIs. This can be seen from Equation 7 where the SCC at lag l depends only on the pairs (S1(i), S1(i + l)) but does not depend on the intervening (l − 1) lags. Higher-order history-dependent effects in the interval sequence S1 can be modeled by Markov chains (Nakahama et al., 1972; van der Heyden et al., 1998). The ISI sequence S1 can be described by a Markov chain of order n, if intervals in the chain are dependent on exactly n preceding intervals. If the intervals are independent, the process is referred to as zero-order Markov (M0). Examples of such processes are the binomially generated spike train (B) and shuffled ISI process M0 described above. The process M1, on the other hand, is first-order Markov because the statistics of the current interval are completely determined given the previous interval.
Consider a sequence of ISIs {jm, jm−1, … , j0}, where jr refers to the r th lag relative to the current ISI j0. For a Markov chain we can define the m th order transition probability as p(j0‖jm, … , j1), which is the probability of observing the interval j0 given that we have observed the sequence {jm, jm−1, … , j1} in the immediate past. Note that the definition of the m th order transition probability does not say anything about the order of the chain itself. The Markov order n of the chain is defined as the smallest value of n for which p(j0‖jm, … , jn, … , j1) = p(j0‖jn, … , j1) for all m ≥ n. Hereafter, we use the symbol m to denote the order of the transition probability, and the symbol n as the fixed number representing the order of the Markov chain. The transition probabilities p(j0‖jm, … , j1) can be estimated from the experimentally observed ISI sequence by counting all occurrences of j0 immediately after the tuple (jm, … , j1).
Given an experimentally observed ISI sequence, we wish to determine the Markov order of the underlying process that generated the sequence. This can be done by comparing transition probabilities obtained from the data with transition probabilities of surrogate spike trains that are constructed to be of known Markov order. Statistical comparisons can be made using the m th order conditional entropy hm as a test statistic (van der Heyden et al., 1998). The hm are defined as:
 Equation 8
Equation 8
 Equation 9for all possible tuples (jm, … , j0) having nonzero joint probability p(jm, … , j0). The conditional entropy satisfy hm+1 ≤ hm, for all m (Shannon, 1948). For an n th order Markov chain, hm = hn for all m ≥ n.
Equation 9for all possible tuples (jm, … , j0) having nonzero joint probability p(jm, … , j0). The conditional entropy satisfy hm+1 ≤ hm, for all m (Shannon, 1948). For an n th order Markov chain, hm = hn for all m ≥ n.
We follow the procedure of van der Heyden et al. (1998)for testing the order of a Markov chain. Hypothesis testing was performed for increasing orders m, beginning with m = 0. The null hypothesis was that the process is Markov order m. The alternative hypothesis was that the process is order (m + 1) or greater. The test statistic was the (m + 1) th order conditional entropy hm+1 given by Equation 9. The statistic hm+1 was evaluated for both afferent and surrogate data sets. A total of Rs = 49 surrogate data sets were generated, and the rank r of the afferent data set was determined. Because the test is one-sided, thep value for the test is p = r/(Rs + 1). The null hypothesis was rejected ifp ≤ 0.05.
Hypothesis testing was performed for increasing orders m until the null hypothesis could not be rejected or until the testing was terminated because of insufficient numbers of surrogate sequences. The criteria for terminating the test was Nm < N/Rs, where N was the number of intervals in S1, and Nm was the number of distinct (m + 1) tuples extracted from the data set. In this case only a lower-bound for the order n could be estimated.
Weak signal detection
The impact of spike train regularity on signal detection performance was estimated for afferents and the three matched spike train models. The detection algorithm was based on an ideal observer paradigm (Green and Swets, 1966) using spike count distributions. For each binary spike train x(i) (see above), signal windows of duration 100 EOD periods were selected at regular intervals of 300 EOD periods. A random offset (uniform between 0 and 99) was added to the starting position of each signal window. A trial consisted of the addition of a constant number of spikes (ns) to each signal window. Spikes were randomly distributed and added only in those EOD periods that did not already contain a spike. A sequence of spike counts was then generated using Equation 2 with T = 100 EOD periods. If the count exceeded a fixed threshold (see below) a “hit” was generated for that counting window. Because the threshold can be exceeded because of random fluctuations in the baseline even when there is no signal present, a percentage of the hits will be false alarms. Let Ns denote the total number of counting windows where signal + baseline is present, with Nhs of these windows receiving a hit. Similarly, let Nb denote the total number of counting windows where only baseline is present, with Nhbof these windows receiving a hit. Then detection probability is given by Pd = Nhs/Ns, and false alarm probability is given by Pfa = Nhb/Nb. The threshold was chosen such that the false alarm probability Pfa was 0.001 or less, motivated by the low rate of false strikes observed in our prey capture studies (Nelson and MacIver, 1999). Trials were repeated for ns = 1, 2, … , 30, and Pd was evaluated as a function of ns.
RESULTS
Baseline spiking activity in the absence of any external stimulus other than the fish's ongoing EOD was recorded from 52 individual P-type afferent fibers in eight fish. The EOD frequency of an individual fish was constant and ranged from 750 to 1000 Hz. Afferent baseline record lengths ranged from 83 to 2048 sec, with a median of 428 sec. The firing rate for individual afferent fibers was nearly constant over the duration of the recording. Baseline firing ranged from 65 to 575 spikes/sec, with a population mean of 260 ± 124 spikes/sec (mean ± SD). These values are in agreement with previously reported results for P-type afferents in this species (Xu et al., 1996).
Interspike interval analysis
The discrete time interspike interval histogram for a representative spike train is shown in Figure 1C. For this unit, ISIs range from 1 to 7 EOD cycles (
 1 = 2.9 EOD periods; CVI(1) = 0.47). Mean ISIs of afferents ranged from 1.4 to 14.2 EOD cycles with a population mean of 4.2 ± 2.3 EOD cycles (Fig. 2A). The coefficient of variation of the ISI distribution ranged from 0.15 to 0.79 with a population mean of 0.44 ± 0.16 (Fig.2B). Thus, on average, the SD of the ISI is ∼44% of the mean, which reflects a considerable degree of variability in the baseline ISI distribution.
1 = 2.9 EOD periods; CVI(1) = 0.47). Mean ISIs of afferents ranged from 1.4 to 14.2 EOD cycles with a population mean of 4.2 ± 2.3 EOD cycles (Fig. 2A). The coefficient of variation of the ISI distribution ranged from 0.15 to 0.79 with a population mean of 0.44 ± 0.16 (Fig.2B). Thus, on average, the SD of the ISI is ∼44% of the mean, which reflects a considerable degree of variability in the baseline ISI distribution.

Population summaries of ISI distributions (N = 52). A, Distribution of mean ISI (
 1). Abscissa is EOD cycles.B, Coefficient of variation of ISI (CVI(1)).
1). Abscissa is EOD cycles.B, Coefficient of variation of ISI (CVI(1)).
A representative joint interval histogram, which provides information about dependencies between adjacent intervals is shown in Figure1D. Long intervals were more likely to be followed by short intervals and vice versa. Almost all fibers demonstrated a similar pattern.
The first-order ISI provides a characterization of spike time variability only on time scales comparable to the mean interspike interval. To characterize spike variability over longer time scales, the statistical properties of the higher-order interval distributions Ik must be considered. In particular it is informative to examine how the SD (ςI(k)), coefficient of variation CVI(k), and the variance-to-mean ratio FI(k) vary as a function of interval order k. These are shown in Figures3A–C respectively, for a representative afferent fiber (○, solid line). The ςI measured in EOD periods (Fig.3A) grows slowly as k increases from 1 to ∼60. Thereafter it increases rapidly (note logarithmic coordinates). Given that the mean of Ik obeys
 k = k
k = k
 1, i.e., it grows linearly with k, the initial slow growth in ςI results in a decrease in the coefficient of variation CVI(k) (Fig. 3B) from an initial value of 0.58 (k = 1) until it reaches a plateau level of ∼0.007 for interval orders k > 100. Thus, for high-order intervals, the SD is ∼0.7% of the mean. This represents a reduction in CVI on long-time scales by a factor of ∼80 relative to the CVI for the ISI. Similarly, for this unit, the variance-to-mean ratio FI(k) drops rapidly with increasing k from an initial value of 0.69 and reaches a minimum value of 0.02 for k = 59. Thereafter, FI increases steadily for larger k. Both the minima in the FI curve and the knee in the CVI curve are a consequence of the transition in the behavior of ςI from slowly varying to rapidly increasing (Fig. 3A).
1, i.e., it grows linearly with k, the initial slow growth in ςI results in a decrease in the coefficient of variation CVI(k) (Fig. 3B) from an initial value of 0.58 (k = 1) until it reaches a plateau level of ∼0.007 for interval orders k > 100. Thus, for high-order intervals, the SD is ∼0.7% of the mean. This represents a reduction in CVI on long-time scales by a factor of ∼80 relative to the CVI for the ISI. Similarly, for this unit, the variance-to-mean ratio FI(k) drops rapidly with increasing k from an initial value of 0.69 and reaches a minimum value of 0.02 for k = 59. Thereafter, FI increases steadily for larger k. Both the minima in the FI curve and the knee in the CVI curve are a consequence of the transition in the behavior of ςI from slowly varying to rapidly increasing (Fig. 3A).

SD (ςI,left), coefficient of variation (CVI,middle), and variance-to-mean ratio (FI,right) of interval distributions. A–C, Representative fiber shown in Figure 1; D–F, medians of population (N = 52). Abscissa is the interval order. Symbols are: afferent data (○) and surrogate data sets from binomialB (□), zeroth-order Markov M0(◊), and first-order Markov M1 (▵) processes. In C, the afferent FI curve exhibits a minimum for interval order kmin = 69 (vertical dashed line). In D–F, the afferent data (○) are medians for the population (N = 52) and the thin lines are upper and lower quartiles. Also shown are renewal processes (binomial, dotted; zeroth-order Markov,dash-dot). The histogram in F represents distribution of kmin in the afferent population (probability on right axis), with mean value of 42 (vertical dashed line).
The trends observed in ςI, CVI and FI for this representative unit were consistent across the entire population. Figure 3D–Fillustrates the population distribution for all 52 fibers by plotting the median value (○, thick line) bracketed by the upper and lower quartiles (thin lines). For each fiber, we also determined the interval order kmin, which gave rise to the minimum variance-to-mean ratio FI (Fig.3C). The kmin were distributed across the population as shown in the gray histogram (Fig.3F). The kmin for the population had a mean value of 42 ± 35. When these values are converted to EOD periods (
 1kmin) or milliseconds (
1kmin) or milliseconds (
 1kmin 10−3/f), they correspond to a mean time of 152 ± 121 EOD periods (or 176 ± 141 msec). The population means for the various measures at kmin were: ςI, 2.9 ± 1.4 EOD periods; CVI, 0.03 ± 0.02; and FI, 0.08 ± 0.07 EOD periods. For 24 of 52 fibers, the SD was <2% of the mean interval length at kmin (Fig.4A). This should be contrasted with the SD of the ISI where the mean CVI(1) for the population was 44% of the mean ISI (Fig.2B).
1kmin 10−3/f), they correspond to a mean time of 152 ± 121 EOD periods (or 176 ± 141 msec). The population means for the various measures at kmin were: ςI, 2.9 ± 1.4 EOD periods; CVI, 0.03 ± 0.02; and FI, 0.08 ± 0.07 EOD periods. For 24 of 52 fibers, the SD was <2% of the mean interval length at kmin (Fig.4A). This should be contrasted with the SD of the ISI where the mean CVI(1) for the population was 44% of the mean ISI (Fig.2B).

Population summaries of coefficient of variation evaluated at the minimum in the variance-to-mean ratio curve.A, CVI for intervals at order k = kmin. B, CVC for spike counts at count window length T = Tmin (see later in Results).
The higher-order interval measures suggest that there may be two different regimes in time demarcated by kmin. When k < kmin, ςIgrows very slowly, and hence, both CVI and FIdecrease as k−1. That is, the interval distribution becomes less variable as k increases. When k > kmin, ςIgrows in proportion to k, and this causes CVI to plateau and FI to increase as k. In this regime, variability increases with increasing k. To analyze and interpret these results, interval statistics for afferents were compared with surrogate spike trains B, M0, and M1 described earlier.
Comparison with renewal process models
Binomial model
For each afferent fiber, a binomial model B was constructed from the p (per-cycle probability of firing) value of the fiber. Under baseline conditions p is a constant and is independent of firing activity in preceding EOD cycles. This model follows from a description of P units as probability coders (see Materials and Methods). The mean p for the population of fibers was 0.31 ± 0.14 and agrees with previously published results (Xu et al., 1996).
ISI and joint interval distributions for a representative fiber are shown in Figure 5, A1 andA2 (same data as in Fig. 1C,D). The corresponding distributions for a binomial model with the same p value are shown in Figure 5, B1 and B2. Although the binomial model has the same p value, and thus the same mean ISI
 1 = 1/p, it does not match the ISI or joint interval distributions of the data.
1 = 1/p, it does not match the ISI or joint interval distributions of the data.

ISI histogram and joint interval histogram of the afferent spike train shown in Figure 1 (column A) and surrogate spike trains obtained from the afferent data (columnsB–D). A1–D1, Show the first-order ISI histograms I1(j), and A2–D2 show the joint interval histogram I(j1, j2) of adjacent ISIs. Size of thecircle is proportional to joint probability. B, The binomial spike train matches the mean ISI
 1, but it does not match either the ISI or joint ISI distributions. C, The zeroth-order Markov spike train (M0) matches only ISI, but not the joint interval distribution. D, The first-order Markov spike train (M1) matches both the ISI and joint ISI of the afferent spike train. ISI sequences for B and M0 are renewal processes, whereas M1 is a nonrenewal process.
1, but it does not match either the ISI or joint ISI distributions. C, The zeroth-order Markov spike train (M0) matches only ISI, but not the joint interval distribution. D, The first-order Markov spike train (M1) matches both the ISI and joint ISI of the afferent spike train. ISI sequences for B and M0 are renewal processes, whereas M1 is a nonrenewal process.
Nevertheless, the binomial model serves as a useful benchmark because the coefficient of variation CVI and variance-to-mean ratio FI can be computed analytically (see Appendix ). For the k th-order interval distribution, ςI(k) =
 /p, CVI(k) =
/p, CVI(k) =
 , and FI(k) = (1 − p)/p = constant. Spike trains generated from this model were subject to the same analysis as the data. These are shown in Figure 3A–C(□, dotted line). Because ςI(k) ∝ k1/2, in logarithmic coordinates, ςI(k) grows linearly with interval order k with a slope of 1/2 (Fig. 3A). It can be seen that the afferent has a much slower increase in ςI for k < 60, but a much faster increase for orders >60. CVI(k) for the afferent data decreases more rapidly with increasing k (nearly as k−1) than the binomial model for which CVI(k) ∝ k−1/2(Fig. 3B, □) but eventually reaches a plateau for large interval orders. The distinction between the binomial model and the afferent data is most strikingly illustrated by the plot of the variance-to-mean ratio FI(k) shown in Figure3C. For the binomial model FI(k) = constant, but the afferent data shows a strong dependence on interval order, initially dropping rapidly (nearly as k−1) and reaching a minimum value for an interval order near 60. The population medians of ςI, CVI, and FI for a binomial process with mean p obtained by averaging over all afferents are also shown in Figure3D–F for comparison.
, and FI(k) = (1 − p)/p = constant. Spike trains generated from this model were subject to the same analysis as the data. These are shown in Figure 3A–C(□, dotted line). Because ςI(k) ∝ k1/2, in logarithmic coordinates, ςI(k) grows linearly with interval order k with a slope of 1/2 (Fig. 3A). It can be seen that the afferent has a much slower increase in ςI for k < 60, but a much faster increase for orders >60. CVI(k) for the afferent data decreases more rapidly with increasing k (nearly as k−1) than the binomial model for which CVI(k) ∝ k−1/2(Fig. 3B, □) but eventually reaches a plateau for large interval orders. The distinction between the binomial model and the afferent data is most strikingly illustrated by the plot of the variance-to-mean ratio FI(k) shown in Figure3C. For the binomial model FI(k) = constant, but the afferent data shows a strong dependence on interval order, initially dropping rapidly (nearly as k−1) and reaching a minimum value for an interval order near 60. The population medians of ςI, CVI, and FI for a binomial process with mean p obtained by averaging over all afferents are also shown in Figure3D–F for comparison.
For each afferent fiber, we also determined the ratio of the FI(kmin) for surrogate divided by afferent. Because the means of Ik are the same for afferent and the surrogate data sets (by construction), the above ratio is also the ratio of the variances of afferent and binomial model at k = kmin. This ratio provides a measure of how much more regular the afferents are in comparison with the binomial process. Figure6A shows the distribution of this number for the population. At k = kmin the afferents exhibited variance-to-mean ratios that were on the average 50 times smaller (mean, 50 ± 27) than the FI for binomial spike trains.

Population summaries of the decrease in interval variance-to-mean ratio (FI) observed in afferents when compared to FI of the matched surrogate spike trains:A, binomial, B, zeroth-order Markov (M0), and C, first-order Markov (M1). Each histogram is the distribution of the ratio of the FI(kmin) for surrogate divided by afferent. It measures the decrease in variability of intervals in afferents with reference to the surrogate spike train. Note different scales on abscissa.
Zeroth-order Markov model (shuffled ISI)
The binomial model agrees with the data only in the mean value of the ISI distribution, but it fails to accurately describe the ISI distribution. The zeroth-order Markov model (M0) was constructed for each afferent by shuffling the ISI sequence S1 for that unit (see Materials and Methods). Thus, it matches the ISI distribution of the afferents. Figure 5, C1 and C2, shows the ISI and joint interval distributions for this model. It can be seen that the model matches the ISI of the afferent (Fig. 5, compare C1,A1), however it does not correctly model the joint interval distribution (Fig. 5, compare C2, A2).
Because M0 is a renewal process, the coefficient of variation CVI and variance-to-mean ratio FIcan be computed analytically (see Appendix ): CVI(k) = CVI(1)/
k, where CVI(k) = Var (I1)1/2/
 1, and FI(k) = Var (I1)/
1, and FI(k) = Var (I1)/
 1 = constant. Results for this model matched to a representative afferent are shown in Figure 3A–C (◊, dash–dot line). Note that ςI(1), CVI(1), and FI(1) (i.e., the y intercepts) are the same for M0 and afferent because M0 was constructed to match the first-order statistics of the data. The population ςI, CVI, and FI curves for this model are shown in Figures3D–F, respectively (dash–dot line).
1 = constant. Results for this model matched to a representative afferent are shown in Figure 3A–C (◊, dash–dot line). Note that ςI(1), CVI(1), and FI(1) (i.e., the y intercepts) are the same for M0 and afferent because M0 was constructed to match the first-order statistics of the data. The population ςI, CVI, and FI curves for this model are shown in Figures3D–F, respectively (dash–dot line).
Although M0 is more regular than the binomial model B, it still does not capture the intermediate-term regularity of the afferent data. At the minimum of the variance-to-mean ratio curve, FI for the data was on average 14 times smaller (mean, 13.8 ± 10.1) than for M0(Fig. 6B). Whereas this is an improvement over the binomial model, the reduction in variability with increasing order of intervals is not as great as that demonstrated by afferents.
The above results show that variability in afferent interval distributions cannot be accounted for by an underlying renewal process. In particular, at the minima in the FI curve, which occurs on a time scale of ∼60 intervals (∼200 msec), afferents have a variance that is an order of magnitude smaller than that predicted by a renewal process. Thus, we must look at nonrenewal properties for a better understanding of this dramatic reduction in spike train variability.
Comparison with nonrenewal models
Renewal models are “memoryless”, that is interval distributions are independent of previous intervals. However, this is not the case for P-type afferent data, as illustrated by the joint interval distribution (Fig. 5A2). Long intervals in the sequence are more likely to be followed by short intervals and vice versa. In contrast, neither of the renewal models (B, M0) discussed above incorporate this dependency, as can be seen from Figure 5, B2 andC2.
The simplest nonrenewal model that incorporates the observed long–short dependency is the first-order Markov process M1 described earlier (see Materials and Methods) where the probability of generating the next interval depends only on the current interval. Figure 5D2 shows the joint interval histogram for the fiber shown in Figure 5A2. By construction, the ISI distribution I1(j1) (Fig. 5D1), joint interval distribution I(j1, j2) (Fig. 5D2), and second-order interval I2(j1) distribution (data not shown) are identical to those of the afferent.
Results for the M1 model are shown in Figure3A–C (▵, dashed line). ςI, CVI, and FI are identical for M1 and afferent for k = 1 and k = 2 (by construction), but thereafter, M1 does not fully capture the continued decrease in variability observed in the afferent data, although it is better than the two renewal models B and M0.
At the minimum order kmin, FI for the afferents was on average a factor of four times smaller than the M1 model (mean, 4 ± 2) (Fig.6C). Thus, even a nonrenewal model that correctly incorporates the long–short correlations exhibited in the data cannot adequately account for the longer term regularity of afferent spike trains. This result indicates that dependencies in the underlying nonrenewal process go beyond the immediately preceding ISI. The analyses in the following sections are intended to address how far back in time the “memory” effect extends.
Interval correlations
Correlations over longer durations were analyzed for each afferent and its matched M1 model using serial correlation coefficients (Eq. 7). Figure7A shows the population distribution of the correlation coefficient between adjacent ISIs (ρ1). The ρ1 ranged from −0.23 to −0.82 with a population mean of −0.52 ± 0.14. That is, all afferents exhibited strong long–short ISI dependency. The distribution of correlation coefficients in the population for lags of 2 and 3 are shown in Figure 7, B and C. Most afferents exhibit positive correlations for lag = 2 (
 2, 0.10 ± 0.18) and weak negative correlations for lag = 3 (
2, 0.10 ± 0.18) and weak negative correlations for lag = 3 (
 3, −0.07 ± 0.11). However, for lags larger than one, the coefficients become smaller, and we used more rigorous statistical criteria to determine the extent and significance of the ρk.
3, −0.07 ± 0.11). However, for lags larger than one, the coefficients become smaller, and we used more rigorous statistical criteria to determine the extent and significance of the ρk.

Population summaries of serial correlation coefficients (ρ) of afferent ISI sequences. A–C, First three lags, ρ1–ρ3, respectively. The vertical dashed line is ρ = 0. The negative correlation for adjacent ISIs (ρ1) reflects the strong long–short dependency in the ISI sequence.
Serial correlation coefficients were estimated for all fibers for the first 10 lags. Coefficients are shown for three representative fibers in Figure 8 (solid line), and the first-order Markov model M1 (dash-dot line). Spike trains from the renewal models B and M0 did not exhibit any correlations (i.e., ρk = 0, for all k) because of independence of ISIs (data not shown). For both afferent and model M1 we used a shuffled data technique to determine the maximum lag k for which the ρk were significantly different from zero (see Materials and Methods).

Representative serial correlation coefficients (ρk, ordinate) for lags k = 1, … , 10 (abscissa). The ρkmeasure correlation between an ISI and the k th preceding ISI. A–C show ρk for three representative afferents (solid line) and for their matched surrogate first-order Markov spike train M1(dash-dot line). Coefficients were tested against the null hypothesis that there was no correlation between the intervals at p = 0.01. The ρk which are significantly different from zero are indicated by *, whereas ○ indicates no significant correlation.
Although all fibers exhibited statistically significant correlations extending back several lags, so did the M1model. In fact, in almost all cases, the M1model showed much stronger correlations than the afferent for all lags k ≥ 2. Thus, even a Markov process that is first-order (M1) can have nonzero SCCs that extend much further back in time than a single interval.
The following example illustrates the converse effect that the SCC for lag l can be small even when there are strong l th order dependencies in the data. To illustrate this point we took the ISI sequence S1 for the representative afferent illustrated in Figure 1 and analyzed the distribution of Y = S1(i), given X = S1(i − 4) for two example patterns: (X, ?, ?, ?, Y) and (X, 2, 2, 2, Y). In the first pattern the “?” represents any arbitrary ISI, i.e., X and Y were not conditioned on the intervening intervals (S1(i − 3), S1(i − 2), S1(i − 1)). However, in the second sequence, X and Y were conditioned on the occurrence of a specific sequence (S1(i − 3) = 2, S1(i − 2) = 2, S1(i − 1) = 2). We then calculated the joint probability of Y given X as for Figure 1D (see Materials and Methods). The results are shown in Figure 9.

An illustration of how correlation analysis may fail to reveal memory effects in spike trains. A, Patterns of four adjacent ISIs (X, ?, ?, ?, Y) where “?” is any arbitrary value, were extracted from the ISI sequence S1 for the afferent shown in Figure 1. The joint probability distribution of X and Y were estimated (probability is proportional to diameter of thecircle). The joint distribution suggests a very weak correlation between X and Y (see Results).B, Patterns of four adjacent ISIs (X, 2, 2, 2, Y) were extracted as in A. The distribution of X and Y is strongly influenced by conditioning it on the intermediate sequence (2, 2, 2). Serial correlation coefficients provide information from the distribution shown in A and not from the conditioned distribution shown in B. Hence, long-term memory effects may not be noticeable from correlation analysis.
Figure 9A shows that X and Y are only weakly correlated (ρ4 = 0.014; p = 0.01). It is useful to compare this histogram with that of the zeroth-order Markov process for the same afferent as shown in Figure5C2. The zeroth-order model is a renewal process where intervals are uncorrelated for all lags k. The similarity between the two histograms suggests a loss of correlation. In contrast, the pattern (X, 2, 2, 2, Y) has a joint distribution shown in Figure 9B, and it can be seen that conditioning very strongly influences the correlation structure of the joint distribution. Because serial correlation analysis is based on unconditioned distributions, long-term memory effects may average out.
Analysis of Markov order
The above examples illustrate the shortcomings of serial correlation analysis of memory effects and indicate that a more direct test of Markov order is needed. Toward this end we applied a statistical test to explicitly test the Markov order of the process (see Materials and Methods). Each afferent was tested against surrogate data sets that were constrained to match the afferent up to a specified order m. The test statistic was the conditional entropy hm+1. Testing began with m = 0 and continued for increasing values of m until the null hypothesis (process is of order m) could not be rejected.
Results for two representative afferents are shown in Figure10, which depicts the hm for afferent (solid line) and mean hm for 49 realizations of the surrogate data (dashed line). For the unit shown in Figure10A, testing showed that afferent data had significantly smaller hm(*) than surrogate data (□) for orders up to 3. For orders 4 and 5, there was no significant difference in the hm (○). It was concluded that this afferent could be described by a third-order Markov process. Testing terminated for only 5 of 52 afferents with the null hypothesis being accepted. Testing also terminated if there was not sufficient data for the afferent. This is shown in Figure 10B, where the afferent and surrogate data sets were significantly different up to fifth-order. There was not sufficient data to test for higher orders, and thus m = 5 is only a lower-bound on the order of the process for this afferent. Testing terminated for the majority of afferents (47 of 52) in this way.

Conditional entropy hm for two representative afferent spike trains (solid line) as a function of order m. The mean hm for 49 surrogate sequences which matched the data exactly up to order (m − 1) are also shown (□, dash line). Afferent hm, which were significantly different from surrogate data are shown as *. Differences between afferent and surrogate data which were not significant are shown as ○. A, Afferent spike train that was described by a third-order Markov process. B, Spike train for which surrogate and afferent data sets had significantly different hm for all orders tested. Testing terminated because of insufficient data. The order of the process was at least 5, i.e., the number represents only a lower-bound. See Table 1 for a summary of testing.
Table 1 summarizes the test for Markov order. The total number of afferents for which the order was at least m are listed for each m in the top row. Of these, the number of afferents for which the order was exactly m are shown in the bottom row. For example, all 52 afferents were at least order 2 (top row, m = 1, 2), with one afferent being exactly order 2 (bottom row, m = 2). Similarly, 51 were at least order 3, of which three afferents were exactly order 3. Thus, discarding the three afferents that were exactly order 3, only 48 afferents were tested for m = 4. Four of these could not be tested because of insufficient data, leaving 44 afferents that were at least order 4 (top row, m = 4). Of these afferents, only one was exactly order 4 (bottom row, m = 4). The test proceeded in this manner until afferents were exhausted. Most afferents (44 of 52) were fourth-order Markov or greater, and approximately a quarter of the units (12 of 52) were seventh-order Markov or greater.
Test of Markov order for N = 52 units
Count distributions
For nonrenewal processes, spike count distributions can provide additional information about the process and can complement higher-order interval analysis. Spike count distributions were analyzed from the count sequence defined by Equation 2. The SD ςC, coefficient of variation CVC, and variance-to-mean ratio FC (also called Fano factor) of the spike count distributions were computed as a function of window duration T. T plays the same role in count analysis as interval order k in interval analysis.
Figure 11A–C shows the statistical measures for the same representative afferent fiber, whose interval analysis was described earlier (Fig. 3A–C). As with interval analysis, spike count distributions exhibited a minimum variance-to-mean ratio (Fano factor FC) at an optimum count window of duration Tmin. For the fiber shown in Figure 11C, Tmin = 280 EOD periods (368 msec) with FC(Tmin) = 0.01 spikes. Mean spike count at Tmin was 94 ± 0.98 spikes, i.e., a SD that is ∼1% of the mean (Fig.11A,B). Beyond this minimum T, counts became more irregular with increasing T because of the rapid increase in SD (Fig. 11A). The trends in ςC, CVC, and FC were observed in all afferents and closely resemble those seen in interval analysis (Fig. 3). Figure11D–F summarizes the median value of ςC, CVC, and FC for the population. The distribution of Tmin across the population is shown in the histogram overlaying the Fano curves in Figure 11F.Mean Tmin for the population was 233 ± 172 EOD periods (270 ± 200 msec), and mean FC(Tmin) for the population was 0.025 ± 0.022. At Tmin when fibers demonstrate most regular counts, the distribution of CVC(Tmin) for the population is shown in Figure 4B. Twenty seven of 52 fibers had SDs that were <2% of mean spike count. Mean CVC(Tmin) for the population was 0.026 ± 0.023.
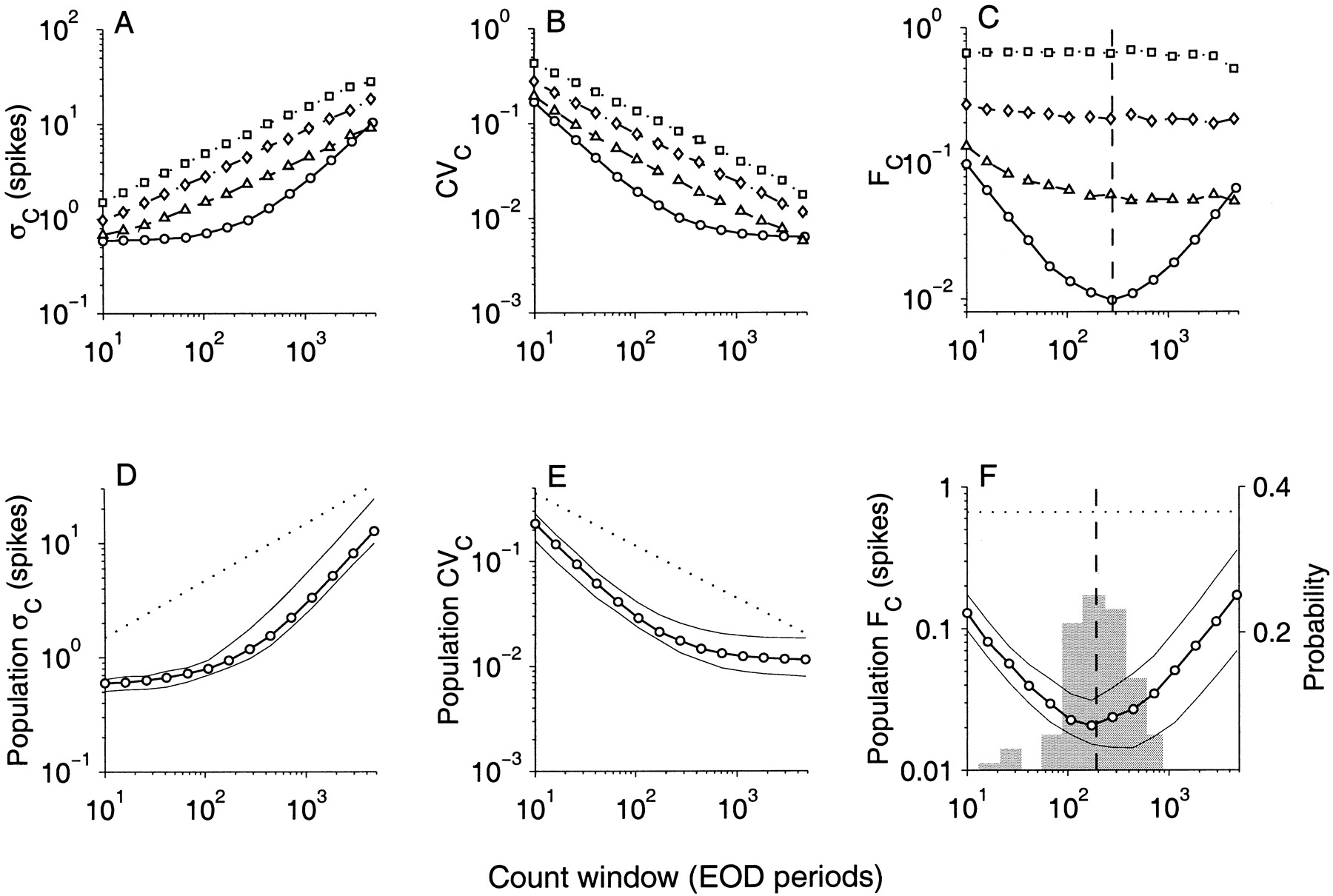
SD (ςC,left), coefficient of variation (CVC,middle), and variance-to-mean ratio (Fano factor FC, right) of spike count distributions.A–C, Representative afferent (same afferent shown in Fig.3A–C). D–F, Medians of population (N = 52). Abscissa is count window duration T in EOD cycles. Symbols and layout follow Figure 3. InC, afferent FC curve exhibits minima when count window Tmin = 280 EOD periods (vertical dashed line). In D–F the dotted line is the median for surrogate binomial data with mean ISI equal to that of the afferent population. The histogram in F is the distribution of Tmin in the afferent population, with mean value Tmin = 233 EOD periods (vertical dashed line).
As was the case for interval analysis, the spike count analysis indicates that the afferents are significantly more regular than the three model spike trains (B, M0, and M1). The improvement in regularity measured as a ratio of the Fano factor of the model to that of the afferent at Tmin is shown in Figure12. The figure is similar to Figure 6. Afferents had Fano factors that were on the average smaller than those of the models by 19.6 ± 10.5 (B, Fig.12A), 6.0 ± 4.7 (M0, Fig. 12B), and 1.7 ± 1.0 (M1, Fig.12C). Thus, the count analysis agrees with interval analysis in that the regularity of afferents cannot be explained by renewal models (B and M0) or even a nonrenewal model that incorporates adjacent interval dependencies (M1).

Population summaries of the decrease in count variance-to-mean ratio (Fano factor, FC) observed in afferents when compared to FC of the matched surrogate spike trains: A, binomial; B, zeroth-order Markov (M0); and C, first-order Markov (M1). Each histogram is the distribution of the ratio of the FC(Tmin) for surrogate divided by afferent. It measures the decrease in spike count variability in the afferents with reference to the surrogate spike trains. Note different scales on abscissa.
Although interval and count analysis are in agreement on the general trends seen in afferent data, it should be noted that there are differences between the two. The most significant difference lies in a determination of the time scale on which afferents may be considered most regular. From interval analysis, the mean time estimated for the population at their kmin was 176 msec (see Interspike interval analysis), which is smaller than the mean Tmin estimated at 270 msec from the count analysis (see above).
Weak signal detection
The regularity of primary electrosensory afferent spike trains is most pronounced for count windows on the order of ∼200 EOD periods (∼200 msec). Here, we illustrate the impact that this spike count regularity could have on detection performance, if the nervous system were to implement a detection algorithm using a comparable integration time constant. Full analysis of the optimal detection algorithm for the actual spatiotemporal profiles of naturally occurring electrosensory signals is beyond the scope of this paper. Here, we demonstrate the magnitude of the effect by considering a simplified signal detection experiment in which the stimulus is assumed to transiently increase the spike count on an individual afferent by a fixed number of spikes ns within a fixed time window.
The detection algorithm is based on an ideal observer paradigm (Green and Swets, 1966) using spike count distributions (see Materials and Methods). It implements a binary hypothesis testing procedure illustrated schematically in Figure13A. In the absence of a stimulus, the spike count is drawn randomly from the baseline spike count distribution (Fig. 13A, Baseline). In the presence of the stimulus, the spike count is assumed to be drawn from a shifted version of the same distribution, with an offset of ns spikes (Fig. 13A,Baseline + Signal). Given an observed spike count, the detection experiment decides which of the two distributions is most likely to have generated the observation. If the count exceeds a fixed threshold (Fig. 13A, Threshold), then we decide that a stimulus event has occurred. This could be a false alarm because of a baseline fluctuation being erroneously classified as a stimulus event (area marked as Pfa under theBaseline curve) or a correct detection if a stimulus was in fact present (area marked as Pd under theBaseline + Signal curve).

Signal detectability in afferent spike trains when spikes are added at random to baseline discharge. A, The detection strategy is based on a binary hypothesis test. In the presence of a signal, the baseline spike count distribution (Baseline) is shifted by an amount equal to the increase in number of spikes caused by signal (Baseline + Signal). A threshold (vertical dashed line) defines the probability of detection (gray area, Pd) and probability of false alarm (black area, Pfa). By constraining Pfa, Pd can be maximized.B, Spikes (abscissa) were added randomly to blocks of T = 100 EOD periods, and a signal detection algorithm (see Results) was given the task of determining whether signal was present subject to Pfa ≤ 0.001. Ordinate is Pd, and abscissa is number of extra spikes caused by signal. Detection experiments were simulated in afferent (○), and surrogate spike trains from binomial (B, □), zeroth-order Markov (M0, ◊), and first order Markov (M1, ▵) processes. For the afferent, signal detection performance at 90% (dashed line) is possible with as few as 2–3 spikes over the baseline of 35 spikes. Surrogate spike trains required more spikes to achieve the same level of performance (see Results).
Simulated signal detection experiments were performed using afferent data from a representative unit, as well as three matched spike train models (B, M0, and M1). The results are shown in Figure13B. In all cases the detection probability Pd increased with increasing signal strength ns, but it increased more rapidly with increasing number of added spikes for the afferent than for any of the three models. If we arbitrarily select Pd = 0.90 for comparison purposes (Fig. 13B,horizontal dashed line), we find that an addition of two or three spikes results in a 90% detection probability for the afferent spike train, whereas a comparable level of performance requires approximately five spikes for M1, 10 spikes for M0, and 18 spikes for the binomial process B. Specifically, comparing results for the afferent data and the best-matched renewal process model M0, we see that the afferent spike train permits efficient and reliable detection of signals that are a factor of 3–5 times weaker than could be detected if baseline activity were generated by a renewal process.
DISCUSSION
The principal finding of this study is the remarkable regularity of P-type afferents on intermediate time scales, given the high variability of their interspike intervals on short time scales. We measured variability of intervals using SD (ςI), coefficient of variation (CVI), and variance-to-mean ratio (FI). Across the population of afferents the coefficient of variation of the first-order ISI, CVI(1) averaged ∼0.44. Higher-order intervals Ik(which are the sums of k successive ISIs) showed a rapid decrease in CVI. On intermediate time scales (k ≈ 50), CVI(k) was <0.02 for most afferents (Fig. 3E). In contrast if the intervals were generated by a renewal process, CVI would decrease as k−1/2, and the expected CVIon intermediate time scale would have been ∼3–5 times larger.
Although CVI is a normalized measure of variability, it is easier to understand the large improvements in regularity of afferents by examining how the standard deviation of intervals ςI changes with k (Fig.3A). For a renewal process ςIincreases as k1/2, but for afferents, there is little increase in ςI up to k ≈ 50 (Fig. 3A). It is as if the spike-generating process were keeping a check on the cumulative deviation of the successive ISIs from the mean ISI. Such a regularizing process could cancel deviations so that overall variability of k successive intervals is approximately the same as the variability of a single interval. If such a process were responsible for the observed regularity it would appear that the process is able to maintain this regularity only over intermediate time scales. This is seen most clearly in the variance-to-mean ratio curve FI(Fig. 3C). The FI curve decreases sharply with increasing k, whereas a renewal process has constant FI. For the afferent data, FI decreases until it reaches a minimum (for some afferent specific kmin), after which it loses regularity and increases with increasing k. The time scale on which the spike regularity is most pronounced relative to a renewal process corresponds to interval order kmin. The distribution of kmin in the population of afferents is shown in the gray histogram of Figure3F. The population mean was
 min = 42, which corresponds to ∼175 msec. Spike count distributions (Fig. 11) demonstrated similar trends, although the estimated time scale over which spike counts were most regular was somewhat larger (270 msec).
min = 42, which corresponds to ∼175 msec. Spike count distributions (Fig. 11) demonstrated similar trends, although the estimated time scale over which spike counts were most regular was somewhat larger (270 msec).
The rapid decrease in variability has implications for signal detection. For a renewal process, to achieve a similar reduction in variability would require a time scale of about kmin2, which is ∼1700 ISIs, or several seconds. Therefore, in situations where sensory signals are extremely weak, the regularization process allows reliable detection using smaller integration times.
Interval and count variability in other sensory systems
The coefficient of variation of the ISI distribution has long been the standard measure for specifying spike train variability. For the benchmark Poisson process, CVI = 1 for all interval orders. Spike trains with CVI > 1 (< 1) are more irregular (regular) than a Poisson process. Spontaneously active neurons demonstrate a wide range in ISI variability with reported values ranging over two orders of magnitude from 0.02 (Ratliff et al., 1968) to ∼3 (Teich et al., 1997). In comparison, the values we report here for P-type electroreceptor afferents had a mean CVI(1) of 0.44 and ranged from 0.15 to 0.79, reflecting moderate to high short-term variability.
For renewal processes, the ISI distribution is sufficient to completely describe variability on all time scales (Cox, 1962). For nonrenewal spike trains, such as P-type afferents reported here, it is necessary to examine higher-order distributions. Towards this end, interval distributions Ik or count distributions CT and their statistical properties can provide useful information about variability. Higher-order interspike interval distributions were first introduced by Rodieck et al. (1962), but with the exception of second-order interval distributions I2 (Teich and Khanna, 1985) they have not been widely used. This is unfortunate because higher-order interval distributions convey useful information about variability on multiple time scales. On the other hand, spike count distributions have been more widely used in recent years. However, they have been used primarily to characterize spike trains for which the Fano factor exhibits power-law growth with count window T, on time scales extending beyond tens of seconds (for review, see Teich et al., 1996). Such spike trains exhibit a high degree of irregularity (FC > 1) that increases with counting time. On the time scales that are of interest to us (0.1–1 sec), most of the reported work on spike count distributions are restricted to driven responses (Teich and Khanna, 1985; Young and Barta, 1986;Relkin and Pelli, 1987; Shofner and Dye, 1989; Softky and Koch, 1993; Baddeley et al., 1997; Shadlen and Newsome, 1998) and cannot be directly compared with the results for baseline responses.
History effects and nonrenewal nature of afferent spike trains
Most experimentally observed spike trains exhibit correlations and memory effects in the ISI sequence. That is, they are described by nonrenewal processes. This is true for all P-type afferents reported here. All afferents had adjacent ISIs that were strongly anticorrelated. Anticorrelations have been noted in spike trains of P-type units in other species of electric fish such as the gymnotidSternopygus (Bullock and Chichibu, 1965) andSteatogenes (Hagiwara and Morita, 1963). They have also been reported in many other sensory systems including visual (Kuffler et al., 1957), auditory (Johnson et al., 1986; Lowen and Teich, 1992), and somatosensory (Amassian et al., 1964), and in motor systems (Calvin and Stevens, 1968). Whereas anticorrelation improves regularity, our results suggest that it is not sufficient to account for the dramatic improvements in regularity observed in P-type afferents. We demonstrated that a first-order Markov process M1 that incorporated the anticorrelations observed in the afferent data could not reproduce the reduction in variability demonstrated by the afferent spike trains with increasing T (Fig. 11). This suggested that dependencies between ISIs persisted over many intervals.
To assess the duration of history-dependent effects, serial correlation coefficients were evaluated. However, SCCs suffer from two problems. First, even a first-order Markov process can have statistically significant correlations that persist over many intervals (Fig. 8). Second, even if a process is higher-order Markov (Fig. 9B), the use of serial correlation coefficients can average out effects of dependencies for lags smaller than the Markov order (Fig.9A). Thus, Figures 8 and 9 demonstrate that the SCCs cannot be used to determine the order of the Markov chain, and an explicit test of Markov order is required (Nakahama et al., 1972). When explicitly tested for the order of the underlying Markov chain, the majority of afferents were typically fourth-order or greater (as also reported by van der Heyden et al., 1998).
The high degree of regularity exhibited by afferents is a consequence of a nonrenewal process that keeps a check on the deviation from the mean firing rate over many ISIs. Typically, when an interval longer than the mean ISI occurs (a “credit”), the next interval will be shorter than the mean (a “debit”). This gives rise to the strong long–short anticorrelations observed in the data. However, when the credit does not get paid back immediately, it is not forgotten. Rather, it is paid back eventually. This is seen from Figure 9Bwhere we evaluated the distribution of Y given the previous occurrence of X in the ISI sequence (X, 2, 2, 2, Y). The joint distribution shows that the long–short distribution of intervals persists even when there are a number of intervening intervals where the debits and credits do not cancel each other. It is likely that the demands placed on a physiological system for maintaining precision or regularity of spiking may be more easily achieved by making adjustments in timing over many intervals rather than over a few intervals. At present the mechanism causing this remarkable degree of precision is unknown. Although mathematical models of the spike-generating process in P-type afferents have been constructed (Longtin and Racicot, 1997b; Longtin, 1998), they do not explain the long-range interval correlations noted here.
Implications for detection of weak sensory signals
The increased spike train regularity that we observe for P-type afferents on intermediate time scales has important implications for the ability of the fish to detect weak electrolocation targets. P-type afferents encode amplitude modulations of the local transdermal voltage caused by nearby objects (Scheich et al., 1973;Bastian, 1981) (for review, see Zakon, 1986). Objects in the water near the fish modulate the transdermal potential and thus modulate the per-cycle firing probability of P-type afferents. Objects that cause a large change in firing probability are easily detected by the animal. However, when the object is small, or far away, or has low electrical contrast with the surrounding water, then the resulting small change in per-cycle firing probability can be obscured by statistical fluctuations in the baseline spike activity. Early studies have established that the behavioral threshold for Apteronotus is <1 μV/cm (Knudsen, 1974). Bastian (1981) extrapolated his data to show that in this range, the change in firing rate of P-type afferents is ∼1 spike/sec. Thus, at threshold levels of performance the expected change in firing rate is <1% (based on a mean discharge rate of 294 spikes/sec as reported by Bastian, 1981).
In behavioral studies of prey capture performed in our laboratory, we have shown that Apteronotus can detect small water fleas (Daphnia magna, 2–3 mm in length) at a distance of ∼2 cm from the electroreceptor array (Nelson and MacIver, 1999). At this distance, the spatial profile of local transdermal voltage change is a Gaussian-like bump with a full width at half maximum of ∼2 cm (Rasnow, 1996; Nelson and MacIver, 1999). During prey capture behavior the fish is typically moving with a relative velocity of ∼10 cm/sec relative to the prey. Thus, as the electrosensory image passes over the receptor array, an individual electroreceptor organ experiences a transient change in transdermal voltage that lasts ∼200 msec. Interestingly, this temporal duration is well matched to the time scale on which P-type afferents show the greatest increase in spike train regularity.
Based on computer reconstructions of electrosensory images from our behavioral studies, we estimate that the peak change in per-cycle firing probability of P-type afferents at the time of prey detection is at most a few percentage of the baseline probability (Nelson and MacIver, 1999). Assuming a typical baseline spike rate of 300 spikes/sec, this corresponds to approximately one extra spike of a total of 60 spikes expected in a 200 msec time window on an individual afferent. This is a weak signal and one that could potentially be difficult to detect given the relatively high variability observed in the first-order ISI distribution.
The neural computations required to detect the dynamically changing spatiotemporal profile across a population of electrosensory afferents could plausibly be implemented by circuitry in the brainstem electrosensory nucleus, the electrosensory lateral line lobe (Shumway, 1989; Metzner et al., 1998). A full analysis of the optimal detection algorithm is beyond the scope of this paper. However, in performing such an analysis, it will be extremely important to take into account the intermediate-term regularity of P-type afferent spike trains afforded by the underlying nonrenewal process. If we performed such an analysis assuming that P-type afferents could be adequately modeled by matching the first-order ISI distribution and assuming a renewal process model, we would overestimate the behavioral threshold by a large factor (Fig.13B). Thus, it is important for sensory physiologists and neural modelers to consider potential effects of nonrenewal statistics when analyzing detection thresholds for weak sensory signals in noisy spike trains.
Appendix
Spike count distributions for discrete-time renewal processes
For spike trains arising from a discrete-time renewal process, the distribution of spike counts can be calculated from the distribution of interspike intervals. To illustrate this, we first present results for the binomial spike train and then derive expressions relating count and interval distributions for arbitrary renewal processes.
For a binomial process with constant per-cycle probability of firing p, the probability of observing an interval of j cycles between successive spikes is:
 Equation 10which is the geometric distribution with mean
Equation 10which is the geometric distribution with mean
 1 = 1/p. In general, the probability of observing an interval j between k successive spikes (i.e., the k th order interval distribution) is:
1 = 1/p. In general, the probability of observing an interval j between k successive spikes (i.e., the k th order interval distribution) is:
 Equation 11with mean
Equation 11with mean
 k = k/p. Equations 10and 11 are the discrete time analogs of the exponential and k th-order gamma distributions, respectively.
k = k/p. Equations 10and 11 are the discrete time analogs of the exponential and k th-order gamma distributions, respectively.
For a binomial process, the number of spikes in a count window of duration T cycles is distributed according to:
 Equation 12where ĈT(k) is the probability of finding k spikes in T cycles.
Equation 12where ĈT(k) is the probability of finding k spikes in T cycles.
For an arbitrary discrete-time spike-generating process, if counting is performed so that the window starts on the cycle immediately after a spike, then the distribution for the number of spikes in a window of size T, N̂T, is related to the distribution of the k th order spike intervals, Sk, by:
 Equation 13In other words, the probability that there are fewer than k spikes in a count window of size T is the same as the probability that the k th order interval is greater than T. The count distribution and interval distribution are therefore related by:
Equation 13In other words, the probability that there are fewer than k spikes in a count window of size T is the same as the probability that the k th order interval is greater than T. The count distribution and interval distribution are therefore related by:
 Equation 14For a renewal process, the ISIs are independent and identically distributed with some known probability density function I1(j). Because any k th order interval of length r can be expressed as r = ∑i=1k ji, where the ji are the intervening ISIs, the renewality condition implies that the k th order interval distribution is the k -fold convolution of I1 with itself (Feller, 1957). That is,
Equation 14For a renewal process, the ISIs are independent and identically distributed with some known probability density function I1(j). Because any k th order interval of length r can be expressed as r = ∑i=1k ji, where the ji are the intervening ISIs, the renewality condition implies that the k th order interval distribution is the k -fold convolution of I1 with itself (Feller, 1957). That is,
 Equation 15For renewal spike trains, we can use Equation 15 to express Ik+1 in terms of Ik. Introducing this into Equation 14, and after some routine algebra, we have:
Equation 15For renewal spike trains, we can use Equation 15 to express Ik+1 in terms of Ik. Introducing this into Equation 14, and after some routine algebra, we have:
 Equation 16From Equation 15 it can be seen that Ik is completely specified if I1 is known, and hence, from Equation 16 count distributions are also known. That is, for a renewal process the ISI distribution I1 is sufficient to completely describe the count distributions.
Equation 16From Equation 15 it can be seen that Ik is completely specified if I1 is known, and hence, from Equation 16 count distributions are also known. That is, for a renewal process the ISI distribution I1 is sufficient to completely describe the count distributions.
As an example, we can obtain the distribution of counts for a binomial spike train (Eq. 12) from the ISI distribution (Eq. 10). Repeated application of Equation 15 with I1 the geometric density given by Equation 10 yields the k th order interval distribution given by Equation 11. Furthermore, inserting Equations 10and 11 into Equation 16 yields the binomial distribution given by Equation 12.
For a nonrenewal process, the chief difficulty lies in relating the ISI distribution I1 to the k th-order interval distributions. That is, neither the convolution expression given by Equation 15 nor the expression for count distribution given by Equation 16 are applicable. Therefore, Equation 14 can be evaluated only if Ik for all k ≥ 1, are known. Thus, for a nonrenewal process, the ISI distribution does not provide information about counts or intervals on multiple time scales.
Appendix
Measures of variability for renewal processes
Let I1 be the ISI distribution for a renewal process, and let
 1 and Var (I1) be its mean and variance, respectively. Then, as the k th-order interval is the sum of k independent random variables, the mean and variance of Ik are k
1 and Var (I1) be its mean and variance, respectively. Then, as the k th-order interval is the sum of k independent random variables, the mean and variance of Ik are k
 1 and k Var (I1), respectively. Thus, the coefficient of variation CVI(k) is:
1 and k Var (I1), respectively. Thus, the coefficient of variation CVI(k) is:
 Equation 17That is, the coefficient of variation decreases as k−1/2. Likewise, the variance-to-mean ratio FI(k) is:
Equation 17That is, the coefficient of variation decreases as k−1/2. Likewise, the variance-to-mean ratio FI(k) is:
 Equation 18For the binomial model, it follows from Equation 11 that
Equation 18For the binomial model, it follows from Equation 11 that
 k = k/p and Var (Ik) = k(1 − p)/p2. Therefore, CVI(k) =
k = k/p and Var (Ik) = k(1 − p)/p2. Therefore, CVI(k) =
 and FI(k) = (1 − p)/p.
and FI(k) = (1 − p)/p.
For a nonrenewal process, Var (Ik) can be related to Var (I1) and the correlation coefficients ρl by Var (Ik) = k Var (I1){1 + 2∑l=1k−1(1 − (
 ))ρl}.
))ρl}.
The coefficient of variation and Fano factor expressions for spike count distributions are more complicated than those for the intervals, with the exception of binomial (and Poisson) processes for which they are easily calculated. For the binomial spike train, it follows from Equation 12 that
 T = Tp and Var (CT) = Tp (1 − p). Thus, CVC(T) =
T = Tp and Var (CT) = Tp (1 − p). Thus, CVC(T) =
 , and falls as T−1/2. The Fano factor FC(T) = 1 − p, and is constant for all T. Any process with FC(T) smaller than this value will exhibit greater regularity in spike counts than the binomial process, and conversely, more irregular processes will have larger values.
, and falls as T−1/2. The Fano factor FC(T) = 1 − p, and is constant for all T. Any process with FC(T) smaller than this value will exhibit greater regularity in spike counts than the binomial process, and conversely, more irregular processes will have larger values.
For small T, FC(T) for any discrete time process will tend to 1 − p where p is the probability of firing in the sampling interval. That is, for counting times T → 1, the process is nearly binomial. For a continuous time process, when the count window Δt → 0 then p → 0. Thus, FC(T) → 1, which is the Fano factor for a Poisson process. That is, we expect spike counts in small count windows to be as irregular as a Poisson process. For renewal processes, the Fano factor for large T asymptotically approaches a constant value that is related to the coefficient of variation of the ISI by the relation, FC(T) ≈ CVI(1)2(Cox and Lewis, 1966). That is, the variability of spike counts is attributable to the variability in interspike intervals.
Footnotes
This research was supported by National Institute of Mental Health Grant R01 MH-49242. We thank Noura Sharabash and Zhian Xu for experimental support and Josina Goense for helpful comments and suggestions on this manuscript.
Correspondence should be addressed to Rama Ratnam, 3317 Beckman Institute, 405 North Mathews Avenue, Urbana, IL 61801. E-mail:ratnam{at}uiuc.edu.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
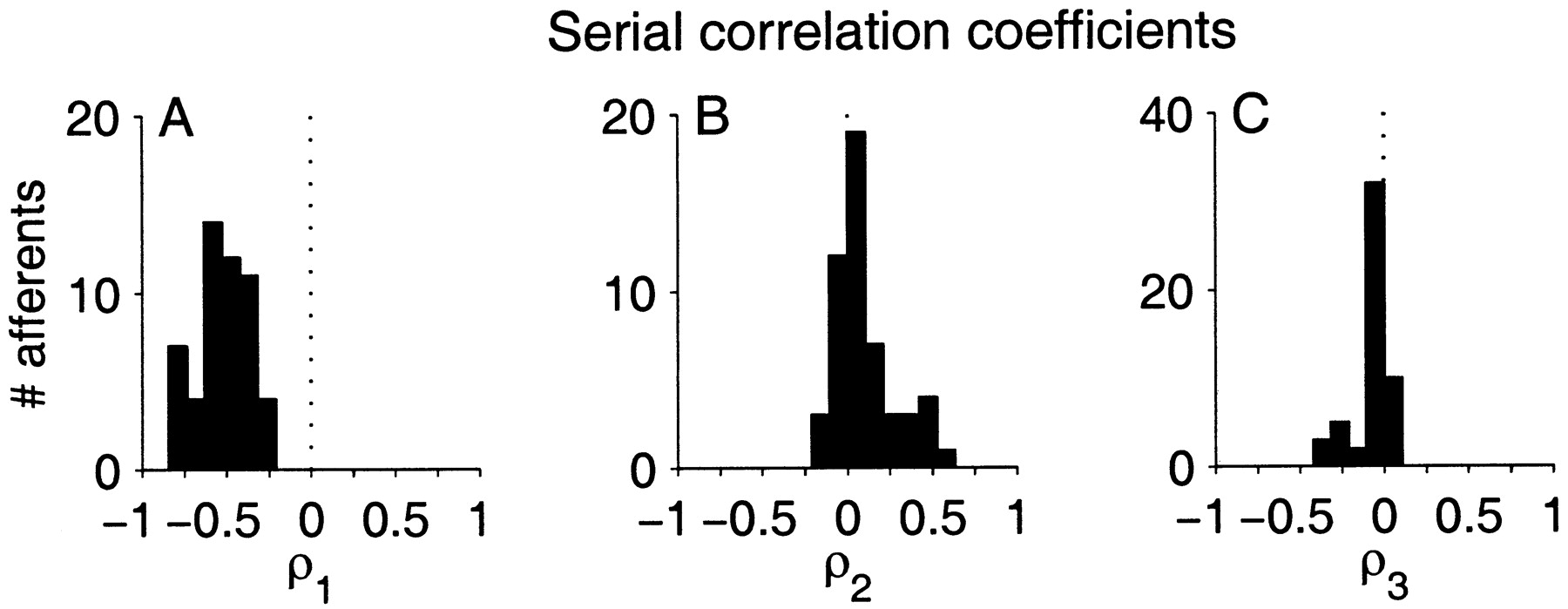{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}