

Article Figures & Data
Figures
- Figure 1.
A, Stimuli. Fourteen actions were used in the experiment. Depending on the action, the reach-to-grasp movement kinematics suggested a precision or a whole-hand grip (e.g., Kinematics A: precision grip use for drinking; Kinematics B: whole-hand grip use for cleaning). B, Experimental conditions. Actions could be performed in three different contexts: congruent, incongruent, and ambiguous. C, Event-related design of the TMS experiment. In a two-alternative forced-choice task, participants watched the videos and predicted which action the model was going to perform. Before making their predictions, participants were requested to pay attention to the kinematic information of the model's hand movements and the contextual information in which these movements were embedded. Each trial began with a frame with the word “attention” on the screen lasting 5000 ms, followed by the video clip, which lasted 400 ms. A single TMS pulse was delivered at three different time delays: 80, 240, and 400 ms after video onset. After the video clip, a frame with the verbal descriptors of two possible goals (e.g., “to drink,” “to clean”; one located up and the other located down) was presented. This frame remained on the screen until a response was recorded.
- Figure 2.
Joint-angle differences (expressed in absolute values, |A-B|°) between actions across contexts (congruent, incongruent, ambiguous) for the index finger flexion (top) and the wrist flexion (bottom). Error bars represent SEM. The video-clip frames below the graph show examples of kinematic measurements; black and white lines denote the measured joint angles.
- Figure 3.
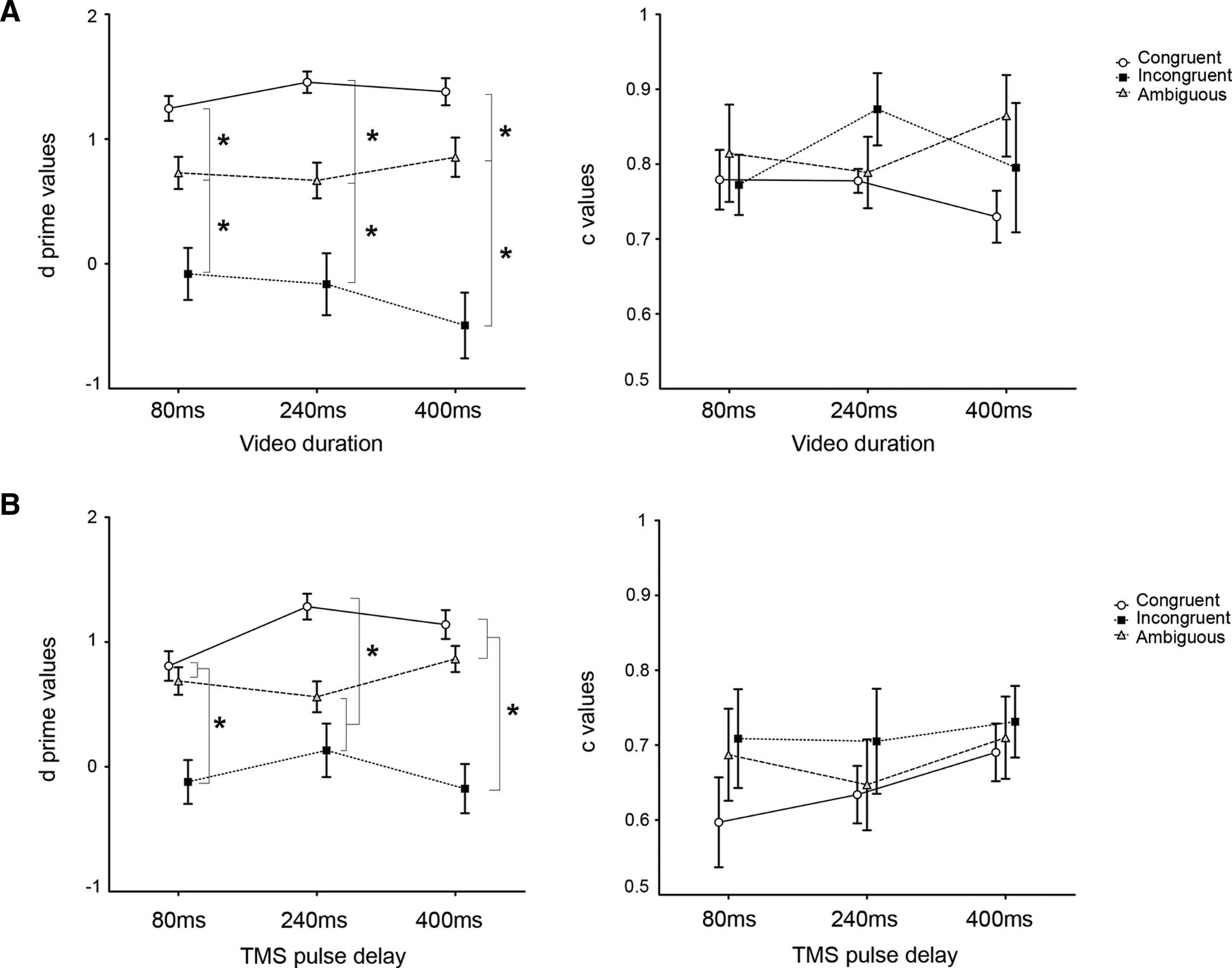
A, B, Participants' performance in predicting the course of the observed actions (expressed as d′) when these were embedded in congruent, incongruent, or ambiguous contexts at the different time points and response criterion (c) for each type of context, within the behavioral (A) and the TMS (B) sessions. Asterisks indicate significant comparison (p < 0.05). Error bars represent SEM.
- Figure 4.
Amplitudes of MEPs recorded from the FDI and FCR muscles during the three action observation conditions (Congruent, Incongruent, and Ambiguous) at the three time points (80, 240, and 400 ms) are expressed as value percentages (%) of the MEPs recorded during baseline. Asterisks indicate significant comparison (p < 0.05). Error bars represent SEM.




Tables
Ambiguous Congruent Incongruent IFF WF IFF WF IFF WF F1 −0.571 ± 2.42 −0.285 ± 1.37 −0.714 ± 1.41 −0.285 ± 1.85 0.714 ± 2.16 0.285 ± 1.06 F2 −1.142 ± 2.67 10 ± 6.37 −2.142 ± 2.2 9.285 ± 6.13 0.01 ± 2.51 11.857 ± 4.88 F3 2.857 ± 1.99 2.714 ± 4.69 −0.714 ± 3.12 5.571 ± 5.46 1.285 ± 2.59 6.142 ± 5.03 F4 0.571 ± 3.42 8.142 ± 5.07 −1.428 ± 3.35 5.857 ± 7.17 1.142 ± 2.59 8.428 ± 4.9 F5 −0.857 ± 3.57 11.714 ± 4.47 −1.142 ± 2.93 7.142 ± 6.73 −1.714 ± 2.78 11.285 ± 5.33 F6 −2.857 ± 4.35 12.285 ± 4.51 −2.142 ± 3.8 10 ± 6.23 −2.571 ± 3.62 10.714 ± 5.29 F7 −5.857 ± 3.95 12.571 ± 4.36 −3.714 ± 2.78 9.142 ± 6.5 −1 ± 5.68 12 ± 5.68 ↵a Values corresponding to joint angle differences (expressed in absolute values, A − B °; ± SEM) between actions across contexts (congruent, incongruent, ambiguous) for the index finger flexion (IFF) and the wrist flexion (WF) in the seven frames of interest (F1: 80 ms; F2: 240 ms; F3: 293 ms; F4: 319 ms; F5: 346 ms; F6: 373 ms; and F7: 400 ms).
TMS session Behavioral session d′ % d′ % 80 ms Ambiguous 0.687 ± 0.11 68.53 ± 2.96 0.728 ± 0.12 66.93 ± 3.38 Congruent 0.808 ± 0.11 78.53 ± 3.36 1.245 ± 0.09 89.06 ± 2.79 Incongruent −0.121 ± 0.17 44.93 ± 5.15 −0.080 ± 0.20 45.46 ± 6.23 240 ms Ambiguous 0.561 ± 0.12 68.6 ± 3.35 0.668 ± 0.14 71.2 ± 3.81 Congruent 1.283 ± 0.10 86.66 ± 2.57 1.455 ± 0.08 92.13 ± 2.5 Incongruent 0.131 ± 0.21 51.06 ± 6.23 −0.163 ± 0.24 44.86 ± 6.55 400 ms Ambiguous 0.864 ± 0.10 73.26 ± 3.29 0.854 ± 0.15 72.86 ± 4.42 Congruent 1.139 ± 0.11 82.4 ± 3.32 1.379 ± 0.10 89.2 ± 2.75 Incongruent −0.175 ± 0.19 48.33 ± 5.56 −0.493 ± 0.26 40.86 ± 7.23 ↵a Values corresponding to d′ and raw percentage of correct responses (mean ± SEM) for each context and time point within the TMS and the behavioral sessions.
TMS session Behavioral session Ambiguous Congruent Incongruent Ambiguous Congruent Incongruent Precision 80 ms 73.57 ± 18.95 79.57 ± 18.73 42.28 ± 23.63 81.42 ± 12.39 94.28 ± 8.84 41.28 ± 17.09 240 ms 78 ± 22.09 83.28 ± 17.55 46.71 ± 18.03 86.71 ± 11.47 90.57 ± 9.6 38.57 ± 23.37 400 ms 78.71 ± 14.79 81 ± 20.81 43.71 ± 18.06 82.71 ± 14.79 87.14 ± 12.11 40.42 ± 24.71 Whole hand 80 ms 62.85 ± 16.71 84.28 ± 19.61 48.42 ± 18.74 62.71 ± 8.49 87.85 ± 9.42 48 ± 24.91 240 ms 62.42 ± 18.55 83.85 ± 15.91 47.85 ± 18.25 56.57 ± 19.29 92.71 ± 9.25 45.28 ± 23.34 400 ms 64.14 ± 18.99 82.85 ± 16.01 54.28 ± 14.75 59.85 ± 20.51 89.57 ± 11.28 44.71 ± 20.86 ↵a Values corresponding to percentage of correct responses (mean ± SD) for precision and whole-hand grips in each context and time point within the TMS and the behavioral sessions.
80 ms 240 ms 400 ms FDI FCR FDI FCR FDI FCR Ambiguous 0.755 ± 0.14 0.489 ± 0.07 0.634 ± 0.13 0.423 ± 0.05 0.579 ± 0.10 0.411 ± 0.05 Congruent 0.661 ± 0.11 0.449 ± 0.06 0.801 ± 0.12 0.471 ± 0.06 0.678 ± 0.14 0.447 ± 0.06 Incongruent 0.637 ± 0.12 0.410 ± 0.05 0.495 ± 0.09 0.383 ± 0.05 0.400 ± 0.10 0.349 ± 0.04 ↵a Amplitudes (mean ± SEM; in millivolts) of MEPs recorded from the FDI and the FCR muscles at three different time points during the observation of actions embedded in ambiguous, congruent, and incongruent contexts.





{kind=link}
{kind=link}
{kind=link}
{kind=link}