

Abstract
An unresolved goal in face perception is to identify brain areas involved in face processing and simultaneously understand the timing of their involvement. Currently, high spatial resolution imaging techniques identify the fusiform gyrus as subserving processing of invariant face features relating to identity. High temporal resolution imaging techniques localize an early latency evoked component—the N/M170—as having a major generator in the fusiform region; however, this evoked component is not believed to be associated with the processing of identity. To resolve this, we used novel magnetoencephalographic beamformer analyses to localize cortical regions in humans spatially with trial-by-trial activity that differentiated faces and objects and to interrogate their functional sensitivity by analyzing the effects of stimulus repetition. This demonstrated a temporal sequence of processing that provides category-level and then item-level invariance. The right fusiform gyrus showed adaptation to faces (not objects) at ∼150 ms after stimulus onset regardless of face identity; however, at the later latency of ∼200–300 ms, this area showed greater adaptation to repeated identity faces than to novel identities. This is consistent with an involvement of the fusiform region in both early and midlatency face-processing operations, with only the latter showing sensitivity to invariant face features relating to identity.
SIGNIFICANCE STATEMENT Neuroimaging techniques with high spatial-resolution have identified brain structures that are reliably activated when viewing faces and techniques with high temporal resolution have identified the time-varying temporal signature of the brain's response to faces. However, until now, colocalizing face-specific mechanisms in both time and space has proven notoriously difficult. Here, we used novel magnetoencephalographic analysis techniques to spatially localize cortical regions with trial-by-trial temporal activity that differentiates between faces and objects and to interrogate their functional sensitivity by analyzing effects of stimulus repetition on the time-locked signal. These analyses confirm a role for the right fusiform region in early to midlatency responses consistent with face identity processing and convincingly deliver upon magnetoencephalography's promise to resolve brain signals in time and space simultaneously.
Introduction
Functional neuroimaging methods with high spatial-resolution, functional magnetic resonance imaging (fMRI) and positron emission tomography (PET) have identified a set of brain structures that are activated when viewing faces. These structures form the core components of an influential neurocognitive model of the human face-processing system (Haxby et al., 2000) that has received broad support in terms of its general claims (Grill-Spector et al., 2004; Winston et al., 2004; Fox et al., 2009), although more recent work continues to fine-tune our understanding of the component nodes of this network and their functional sensitivities (Said et al., 2010; van den Hurk et al., 2011; Harris et al., 2012; Mende-Siedlecki et al., 2013; Baseler et al., 2014).
The high temporal resolution neuroimaging techniques magnetoencephalography (MEG) and electroencephalography (EEG) have also examined the brain's response to faces. Time-locked averaging of M/EEG data across many trials reveals the temporal structure of the brain's event-related response to different types of stimuli. Such analyses have identified temporal signatures of the evoked brain signal that show categorical sensitivity with respect to faces. These include the N/M170 component, which is generally reported to show a larger amplitude to faces than to other types of stimuli (Bentin et al., 1996; Liu et al., 2000; Rossion and Jacques, 2008; Eimer, 2011), and the N/M250 component, which is larger to known than unknown faces in both EEG (Schweinberger et al., 2002; Itier et al., 2006; Schweinberger, 2011) and MEG (Schweinberger et al., 2007) and has been shown to grow in amplitude as a consequence of increasing familiarity within a single experimental session (Kaufmann et al., 2009).
These electromagnetic signatures are widely held to reflect the actions of the same distributed network of generators with metabolic consequences that are measured by PET and fMRI (Johnston et al., 2005; Sadeh et al., 2010; Eimer, 2011; Rossion and Jacques, 2011). However, although a number of source localization studies support the general plausibility of this idea (Halgren et al., 2000; Itier and Taylor, 2004; Itier et al., 2006; Deffke et al., 2007; Bayle and Taylor, 2010; Gao et al., 2013; Perry and Singh, 2014), none of these demonstrates differential functional sensitivity to faces and objects that is localized simultaneously in space and time across the duration of the evoked response (Rossion and Jacques, 2011). Therefore, a detailed characterization of the face-processing network that incorporates information with respect to both location of involved brain structures and the timing of their involvement has not yet been fully realized. Moreover, there is currently a critical mismatch between the conclusions drawn from fMRI/PET studies and from EEG/MEG studies because the former identify the fusiform region with the processing of invariant face features relating to person identity and the latter identify this same region as a generator of the N/M170; however, this evoked component is not believed to encode facial identity (Eimer, 2011; Schweinberger, 2011).
As Rossion and Jacques (2011) point out, a more adequate understanding of the temporal characteristics of the face-processing network's functional sensitivities might be achieved through the use of adaptation paradigms similar to those used in fMRI studies (Andrews and Ewbank, 2004; Ewbank and Andrews, 2008). Such methods demonstrate reductions in brain activity to the repetitions of particular stimulus characteristics that are believed to reflect habituated responding in neurons that are sensitive to those characteristics (Grill-Spector and Malach, 2001). Such methods provide evidence supporting dissociable roles for the fusiform face area (FFA) and superior temporal sulcus (STS) as proposed by the Haxby model (Andrews and Ewbank, 2004) and suggest that identity representations in the ventral temporal cortex may be mediated by face familiarity (Ewbank and Andrews, 2008). Here, we sought to determine the spatiotemporal functional characteristics of the brain systems involved in processing invariant facial attributes, comparing the evoked responses to faces and objects using an adaptation paradigm (Amihai et al., 2011; Mercure et al., 2011) in conjunction with a novel beamformer metric.
Materials and Methods
Overview and hypotheses
In MEG, participants viewed sequential pairs whereby the first “adaptor” stimulus (face or object) was replaced either by a slightly different image of the same identity exemplar, or by a different exemplar from the same category (the “adapted” stimulus). Analysis of MEG data proceeded via a two-stage process. Stage 1 of the analysis focused solely upon the evoked response to the initial adaptor stimuli and aimed to localize cortical regions with responses that were consistently different from faces compared with objects. We achieved this through applying a novel beamformer metric (the Difference Stability Index: DSI). This allowed us to identify a set of MNI coordinates for brain areas with activational profiles in response to the adaptor stimuli that maximally discriminated between faces and objects.
In Stage 2 of the analysis, we extract estimated time series representing the evoked response to the entire duration of the trial (that is to both adaptor and adapted stimuli) for the set of MNI coordinates that we had identified in Stage 1. We then compared the evoked response time series to the adaptor versus adapted stimuli, and across “same” and “different” identity adapted stimuli. We reasoned that cortical locations showing categorical sensitivity to faces should show an attenuation of the evoked signal for the repeated presentation of faces but not objects regardless of whether the adapted stimuli was the same identity as the adaptor. We call such effects “category-level adaptation.” We further reasoned that brain regions involved in the processing of invariant face features would show differential adaptation to same versus different identity adapted faces but not objects. We call these effects “item-level adaptation.”
We hypothesized that we should see localized category-level adaptation to faces but not objects with a latency consistent with the M170 in the fusiform gyrus. We further hypothesized that we should see localized item-level adaptation to faces but not objects with a latency consistent with M250.
Participants.
Of 20 participants recruited, one failed to complete the testing session and two had major motion artifacts in their data and thus were not included in the analyses. Of the 17 participants contributing to the analyses, 11 were female and the mean age was 24.8 (SD = 3.7).
Stimuli.
The stimuli consisted of three categories (faces, objects, and potatoes), with each category having eight different exemplars; for each exemplar, there were four images depicting slightly different viewpoints. The face category consisted of four male and four female Caucasian faces, with neutral expressions presented in a near frontal view taken from the “Aberdeen” stimulus set at the University of Stirling (pics.stir.ac.uk). The object category consisted of photographic images of eight distinct objects: a hat, a wellington boot, a bunch of five bananas, a teapot, sunglasses in their protective case, a cooking pot, a toy cash register, and a vase. There were four distinct viewpoints for each of these objects. The potato category contained images of a range of different varieties of potato. As with the other stimulus categories, there were eight distinct identity potato exemplars, each having four different viewpoints. The original intention of including the potato category stimuli was to include a category of objects for which the exemplars were highly similar, but for which individual exemplars could be distinguished as such. Because our final analysis pathway relies upon the analysis of the stability of differences in evoked signals between pairs of conditions and because our primary research questions relate patterns of brain activity in response to faces versus objects, brain responses to the potato category are not analyzed here. All stimulus images were 400 mm × 489 mm (72 dpi).
Experimental paradigm.
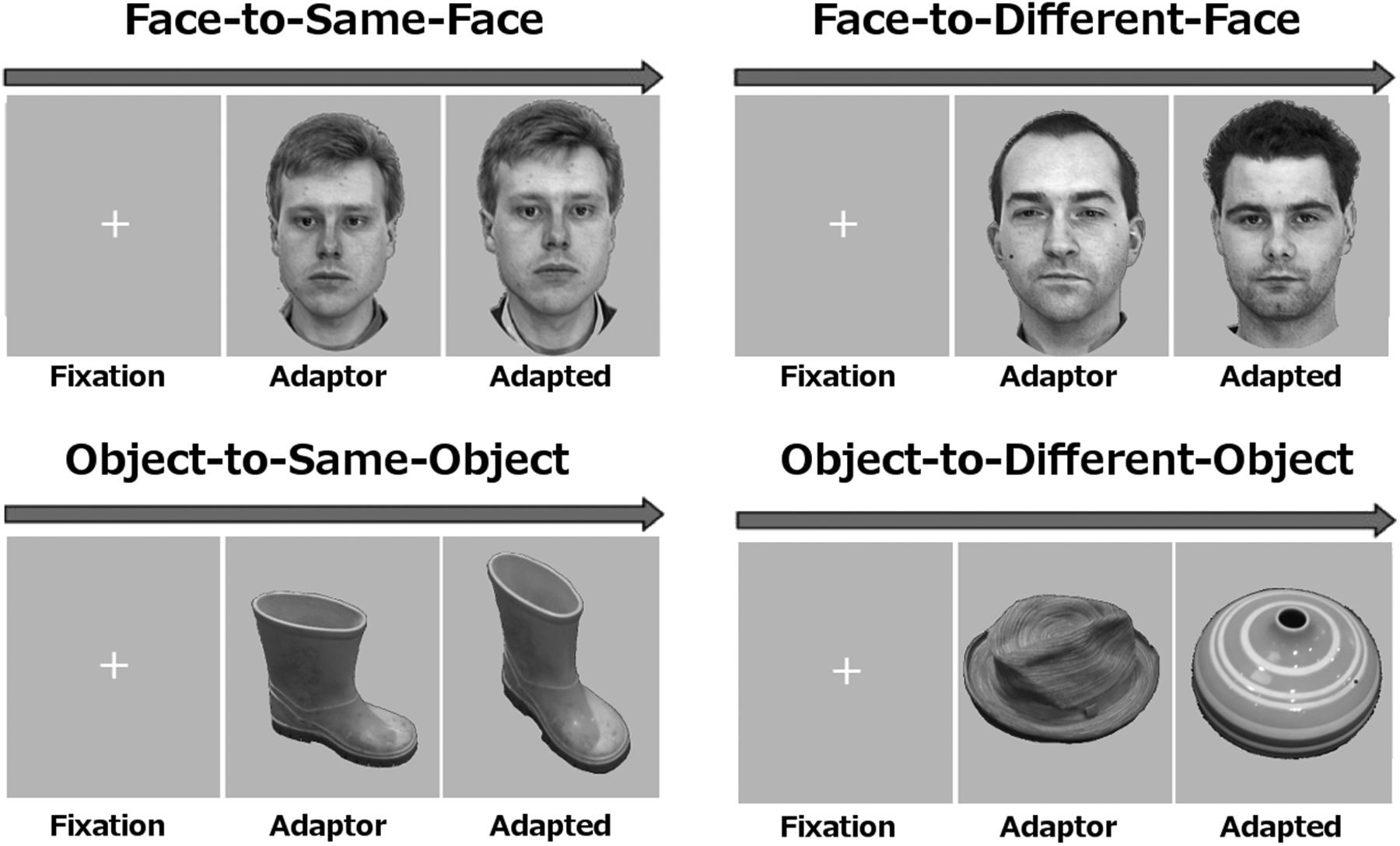
Each trial consisted of a white fixation cross on a gray background, which lasted between 450 and 1000 ms, an adaptor stimulus that was presented for 1017 ms, followed by an adapted stimulus of the same category (faces or objects) that could be either a slightly different image of the same identity exemplar or a different identity exemplar of the category, which was also presented for 1017 ms. The adapted stimulus replaced the adaptor stimulus with no intervening interstimulus interval. Examples of stimulation sequences are shown in Figure 1. There were six conditions: face-to-same-face, face-to-different-face, object-to-same-object, object-to-different-object, potato-to-same-potato, and potato-to-different-potato. There were 112 trials of each type and a further 32 catch trials in which the adapted stimulus contained small red spot at some point close to the center of the image. Participants were instructed to respond to catch-trials with a button press. The Eprime version 2.0 software was used to present stimuli and to record participant responses. Images were presented centrally at a distance of 120 cm and subtended a visual angle of ∼5 degrees.

Examples of stimuli and trial sequences for face-to-same-face, face-to-different-face, object-to-same-object, and object-to-different-object trials. Fixation periods varied between 450 and 1000 ms. Both adaptor and adapted stimuli were displayed for 1017 ms with zero interstimulus interval.
MEG data acquisition and coregistration with structural MRI.
MEG data were acquired on a 4D Neuroimaging Magnes 3600 system with 248 magnetometer sensors. The data were recorded at 678.17 Hz with an online 200 Hz low-pass filter for ∼34 min. The acquisition duration varied depending on the randomization of the interstimulus interval. Three sensors were identified as performing poorly and were excluded from the data analysis for all participants. Head movement within the sensor helmet was assessed using five fiducial head-coils and a movement threshold of <0.8 cm was used as a threshold for acceptance. Each channel of the 704 epochs of data for each participant was visually inspected to look for stray magnetic fields or physiological artifacts such as blinks, swallows, or movement. Of the 17 participants whose data were analyzed, a mean of 31.2 epochs were rejected (SD = 20.0).
The location of five fiducial landmarks and a digital head shape were recorded before acquisition using a Polhemus Fastrack 3D digitizer. To enable anatomical inference in source space, each individual's digitized head shape was coregistered with an anatomical MRI scan using surface matching (Kozinska et al., 2001). A high-resolution T1-weighted structural MRI was acquired using a GE 3.0 T HDx Excite MRI scanner with an eight-channel head coil and a sagittal isotropic 3D fast spoiled gradient-recalled echo sequence. The spatial resolution of the scan was 1.13 × 1.13 × 1.0 mm, reconstructed to 1 mm isotropic resolution, with a TR/TE/flip angle of 7.8 ms/3 ms/20 degrees. The field of view was 290 × 290 × 176 and in-plane resolution was 256 × 256 × 176.
MEG data analysis stage 1: localizing differential evoked responses to faces and objects using the DSI spatial beamformer metric
Overview.
To identify brain regions that respond differently to faces and objects, we performed a beamforming analysis using a novel metric to generate time series estimates at each location of a defined source-space within the brain. The beamforming technique generates a “virtual electrode” (VE) time series for each epoch of data in both the face and object conditions, which gives us a model of the temporal activity at each location on a 5 mm grid cast across the whole brain. The novel metric we use on this beamforming data is the DSI, which generates a measure of the stability of difference waveforms created by subtracting pairs of time series drawn from the faces and objects conditions. The stability measure is based upon correlating averages of the difference waveforms and thus is based upon temporal stability rather than absolute amplitude of the evoked response. This stability index therefore essentially calculates where there is a replicable and stable evoked response to difference waveforms of unaveraged epochs of data for the two conditions. For statistical inference, we use a nonparametric sign-flip permutation method to generate null datasets in which any evoked activity is destroyed to determine whether the stability of the difference waveforms is greater than would be expected from randomly varying data. Therefore, if the average difference waveforms are highly stable, we would expect this to be highly significantly different from the randomly varying null data. A crucial point to note is that a significant DSI value indicates a stable difference (or difference in stability) in the evoked time series at a particular brain location, not necessarily a difference in the amplitude of the response to the compared conditions.
Details of implementation.
The spatial beamformer relies upon analysis of the covariance structure across a set of trials. Because of this, temporal segments of the trials for which there is no discernible evoked signal (i.e., the measurement is dominated by noise) hamper the determination of a set of weights that maximize the beamformer's precision in inverting the sensor-level signal. For this reason, we defined a time window that attempts to maximize the inclusion of time points where (on average) brain signals are present while excluding time points where (on average) brain signals are absent. To define a window of interest, we calculated the root mean square (RMS) across all sensors for each individual in the face condition and then averaged these across participants. From these data, we identified the RMS minima, which indicated the likely boundaries between evoked events. To define our analysis window, the first poststimulus reversal was used as the start of our analysis window and the first reversal below prestimulus RMS levels was used as the end of the window. From this, we defined a time window starting at 60 ms after stimulus onset to 522 ms after stimulus onset as characterizing the temporal boundaries of the evoked response at the group level (Fig. 2). This time window was used to define the temporal limits of subsequent DSI analyses.
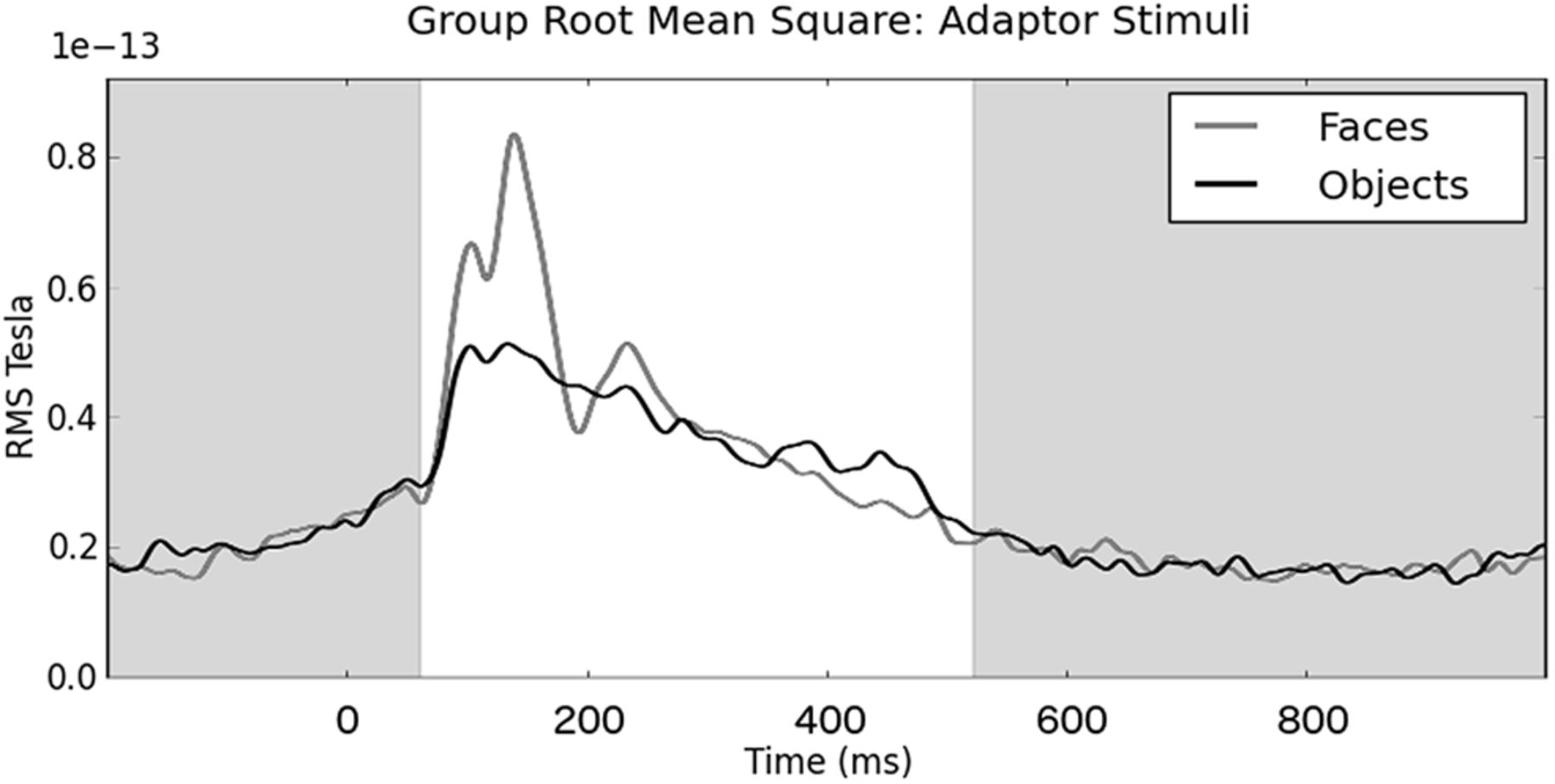
Grand-averaged RMS MEG signal across all sensors, trials, and participants for adaptor face and adaptor object stimuli. The white background area denotes the time window used for the beamformer analysis.
The source space analysis performed for this work was based on a vectorized, linearly constrained minimum variance beamformer (Van Veen et al., 1997), referred to here as the van Veen beamformer. This differs in important ways from the other major class of beamformer (the Huang beamformer; Huang et al., 2004): the van Veen beamformer computes a single, 3D spatial filter, whereas the Huang beamformer is made up of three orthogonal, 1D spatial filters. This apparently subtle difference has significant effects on the reconstructed time series, as discussed in Johnson et al. (2011). In the current work, a time domain rather than power-based metric is used and orientation effects are examined. In these circumstances, it is suggested that the van Veen implementation be used (Johnson et al., 2011). Therefore, the “weights” of the beamformer solution were calculated using Equation 1 as follows:
 where Wk is the 3D weight vector for point k, Lk is the 3D lead field for point k, and Cr is the regularized estimate of the covariance. Here, regularization was applied using the smallest eigenvalue of C. Covariance estimates were based on the time window starting at 60 ms after stimulus onset to 522 ms after stimulus onset (for the adaptor stimulus) across all face and object trials.
where Wk is the 3D weight vector for point k, Lk is the 3D lead field for point k, and Cr is the regularized estimate of the covariance. Here, regularization was applied using the smallest eigenvalue of C. Covariance estimates were based on the time window starting at 60 ms after stimulus onset to 522 ms after stimulus onset (for the adaptor stimulus) across all face and object trials.
These weights, when applied to the recorded data, yield a 3D time series or VE. One advantage of the van Veen formulation is that this 3D VE can be projected onto any direction without recalculation of the weights, which is not possible with the Huang implementation. This allows for a more straightforward and computationally efficient search across orientation. In this work, the orientations were chosen using regular, 10 degree steps of elevation from the x–y plane and evenly spaced steps of azimuth in the x–y plane, the size of which depend on the angle of elevation. This results in 163 orientations, with the nearest neighbor angles separated by a mean of 10.47 degrees (minimum 10.0, maximum 11.83) and no orientation in the hemisphere further than 9 degrees from one of the sampled orientations.
For each of these projected VEs, a DSI was calculated between two conditions of interest. The DSI is an extension of the Source Stability Index (SSI) described by Hymers et al. (2010). In the SSI, VEs for a single condition are examined for the stability of the phase-locked time course. In the DSI, the stability of the difference between two VEs is calculated for a given location and orientation. Once this difference time series has been calculated, the analysis is identical to that for the SSI: the difference time series are split into two equal groups, an average of each group taken, and their correlation calculated. This splitting, averaging, and correlating is repeated 50 times and the average correlation is termed the DSI.
A complete summary of the calculation of the DSI for a point in the brain is outlined below:
Beamformer weights are calculated for a point in the brain k, using Equation 1 where the covariance C is calculated to include the two conditions/time windows being compared.
A 3D time series for each condition/time window is calculated and the difference time series taken for each epoch.
This 3D difference time series is projected onto one of 163 orientations spanning a hemisphere.
For each projection, the following steps are repeated 50 times:
The difference time series epochs are randomly split into two sets, A and B, each containing half of the epochs.
The mean of the epochs in set A and B is generated and a correlation coefficient between the two calculated using the following equation:

The mean of the correlation coefficients is calculated across the 50 repetitions. This mean is termed the DSI.
The maximum DSI across orientations and the orientation at which it occurred is taken forward as the DSI for that location.

To combine DSI metrics across the group, they were first converted to parametric t-statistics comparing the measured DSI with DSIs found for “null” data. The null data were generated by sign flipping half of the difference time series, equivalent to labeling exchange between the two conditions/time windows used to generate that difference time series. If the labeling is arbitrary, that is, if there is no stable, significant difference between the time series, this will generate a null dataset with a similar DSI to that of the “true” data. Exchanging the labels of data that do show a stable difference(s) in their time series will attenuate or destroy that difference and so generate a lower DSI for null data, leading to a difference between the DSI of measured data and the distribution of DSIs for null data. For every null dataset, the DSI was calculated in exactly the same way, including maximizing across orientation, as described above. This leads to a distribution of null DSIs that were Fisher's z transformed to improve the stability of the variance across the range of DSI values and compared with the Fisher's-z-transformed DSI of the real data, giving a parametric t-statistic for each grid point in every participant. This process of using the observed phase-locked response and comparing it with so-called plus-minus averaged data has been used previously (Robinson, 2004).
The overall principle of nonparametric statistics is that the measured data are manipulated and resampled many times to build up a statistical null distribution. The threshold to be applied to the observed data is then determined by the null distribution obtained using these random permutations. Maximum statistics can then be used to account for the multiple-comparison problem as shown by Nichols and Holmes (2002). This involves taking the highest value throughout the volume from each permutation based upon the omnibus hypothesis that if the largest value is not significant, then there are no other voxels in the volume that are.
In this case, group analysis was performed using the t-statistics generated at the individual level. They were first converted to z statistics, spatially normalized to gridpoints based upon the MNI template (using the flirt tool from the FSL neuroimaging analysis package), and then averaged across participants to generate a group image. To determine the empirical threshold, group nulls were generated by randomly sign flipping some of the individual volumetric z statistics and computing the average across the group as above. The maximum value across the volume was taken for this null and a distribution characterized for multiple nulls. In this work, 10,000 permutations were calculated to generate the null distribution. DSI values that exceeded the 95th percentile of the null distribution were considered to be significant. It should be noted that, by constructing null distributions based upon the maximum pseudo-t based upon permutation statistics across all of the grid points within the brain volume, this method implicitly accounts for multiple comparisons across the entire set of tests.
Stage 2: analysis of evoked time series at selected VE locations
Overview.
For a set of selected VEs showing DSI maxima (the activational profiles of which maximally discriminated between responses to adaptor faces and adaptor objects), we extracted estimated time series representing the evoked response to the entire duration of the trial. Responses to adaptor and adapted stimuli were compared using a permutation based t-statistics. For each stimulus category (faces and objects), we compared the response to adaptor versus adapted stimuli to determine whether category-level adaptation occurred. We also compared the response to adapted same versus adapted different stimuli to test whether there was item-level adaptation.
Details of implementation.
Once group VEs were extracted, time points or temporal segments of significant difference were calculated using a permutation methodology similar to that used in the volumetric maps of DSI. To ensure that evoked components had the same polarity across all participants, we applied a permutation method that maximized the RMS of the group-averaged time series by iteratively performing sign flips across each of the members contributing to the average. This ensured the best possible match across participants for the polarity of the evoked components across the duration of the evoked response. Difference waveforms were then calculated for each individual's evoked time series to each condition of interest and converted to a group time series of t-statistics, indicating how nonzero the group difference time series was. Individual difference VEs were then randomly sign flipped and a null group time series of t-statistics calculated.
A fundamental characteristic of evoked brain responses is that early-latency responses tend to be high-amplitude, temporally constrained peaks that have a similar latency across participants, whereas later-latency components tend to be lower-amplitude, temporally dispersed responses that show greater interindividual variability in the latency of their peak amplitudes (Handy, 2005; Litvak et al., 2011). This makes a “one size fits all” approach to analyses somewhat challenging. In fact, it is common practice (and indeed recommended practice—see Handy, 2005) to use different analysis strategies when looking at early latency components compared with later latency components. We therefore performed two analyses for each contrast of interest—a time point-by-time point comparison aimed at isolating differences between conditions in the early-latency peak components and a height-thresholded temporal cluster analyses to test for differences in the later components.
To examine point-by-point differences, the maximum t-statistic across time for each null time series was taken to build a distribution from which to draw nonparametric, empirical thresholds for instantaneous differences between VEs. t-statistics exceeding the 95th percentile of the null distribution were considered to be significant.
Although this method is sufficient to distinguish high-amplitude differences, it may miss smaller but more sustained differences. To examine these effects, a cluster analysis was also performed. In this case, a primary, parametric threshold was set at p = 0.05 and clusters of time points at which the t-statistic of the difference time series was above this threshold were integrated. In the same way as for the point-by-point analysis, null time series were calculated, with the maximum cluster size for each null contributing to the distribution from which cluster thresholds were drawn. Integrated cluster values that exceeded the 95th percentile of the null distribution were considered to be significant.
Results
Spatial localization of stable differences in evoked signals to faces and objects
DSI values were generated for comparing the evoked responses to faces versus objects in response to the onset of the adaptor stimulus. These analyses revealed statistically significant differences in stable evoked responses to faces and objects across regions of the occipitotemporal cortices and the left temporal pole, generally consistent with brain areas known to be involved in the processing of complex visual stimuli (Fig. 3). Locations of peak DSI values are reported in Table 1.

Top, right, and back views of glass brains showing the anatomical locations of brain areas with significant DSI values for the comparison of faces versus objects for the adaptor stimulus (top). Only DSI values exceeding the 95th percentile of observed values and meeting significance criteria are shown. Axial slices showing the locations of VEs are at the bottom.
Locations of peak DSI values
VE analyses of adaptation of the evoked signal
Evoked time series data were estimated for VEs placed at locations showing peak DSI values (we restricted analyses to peak locations that were at least 30 mm apart). Therefore, VE analysis was focused upon five cortical locations: left occipital pole, right lateral occipital cortex, right fusiform gyrus, left lateral occipital cortex, and left temporal pole. Comparison waveforms for selected VEs are shown in Figure 4.

Estimated time series at selected VEs showing category-level adaptation and item-level adaptation to faces and objects. Areas shaded red denote significant differences between conditions on the basis of point-by-point analyses. Areas shaded gray denote differences between conditions on the basis of temporal cluster analyses.
Category-level adaptation: adaptor stimulus versus adapted stimulus for faces and objects
Point-by-point analysis revealed that the occipital pole VE (MNI −12, −91, −12) showed reductions in signal amplitude to adapted faces between 120 and 136 ms after stimulus onset (p < 0.05 corrected) and to adapted objects between 124 and 129 ms after stimulus onset (p < 0.05 corrected; shaded red in Fig. 4), both of these being consistent with category-level adaptation to both faces and objects of M170. Temporal cluster analysis revealed signal amplitude reductions to adapted objects between 167 and 244 ms after stimulus onset (p < 0.05 corrected; shaded gray in Fig. 4), consistent with category-level adaptation to objects of the M250. These analyses also showed a temporal cluster (between 162 and 242 ms after stimulus onset) in which there was reduced signal amplitude to adapted faces, which approached significance (p = 0.06 corrected).
At the fusiform gyrus VE (MNI 33, −51, −7), point-by-point analysis revealed reductions in signal amplitude to adapted faces at periods between 130 and 144, 180 and 186, and 231 and 247 ms after stimulus onset (all p < 0.05 corrected). Temporal cluster analysis revealed amplitude reductions to adapted faces between 170 and 282 ms after stimulus onset. This is consistent with category-level adaptation to faces of both the M170 and the M250. There were no differences in signal amplitudes to adaptor objects versus adapted objects revealed by either the point-by-point analysis or the temporal cluster analysis.
For left lateral occipital cortex VE (MNI −47, −66, −17), point-by-point analysis revealed reductions in signal amplitude to adapted faces at periods between 136 and 141 ms after stimulus onset (p < 0.05 corrected) and temporal cluster analysis revealed reduced activation to adapted faces between 182 and 262 ms after stimulus onset (p < 0.05 corrected). This is consistent with category-level adaptation to faces of both the M170 and the M250. There were no differences in signal amplitudes to adaptor objects versus adapted objects revealed by either the point-by-point analysis or the temporal cluster analysis.
For both the right lateral occipital cortex VE (MNI 33, −96, −7) and the left temporal pole VE (MNI −32, 9, −42), there were no differences in signal amplitude to the adaptor and adapted stimuli to either faces or objects revealed by either the point-by-point or the temporal cluster analyses.
Item-level adaptation: “same” adapted stimulus versus “different” adapted stimulus for faces and objects
At the fusiform gyrus VE (MNI 33, −51, −7), temporal cluster analysis revealed that there were differences in signal amplitude to adapted same faces compared with adapted difference faces between 207 and 298 ms after stimulus onset (p < 0.05 corrected). Because adapted same faces had a lower amplitude signal across the duration of this period, this is consistent with item-level adaptation of the M250. There was no evidence of differential adaptation to adapted same objects versus adapted different objects at this VE location.
Neither the point-by-point analysis nor the temporal cluster analysis revealed any significant differences for the within category adapted same versus adapted different faces or objects at any of the other VE locations.
Discussion
MEG data showed identifiable evoked components M1, M170, and M250 with latencies consistent with the existing literature (Halgren et al., 2000; Itier and Taylor, 2004; Deffke et al., 2007; Bayle and Taylor, 2010; Rossion and Jacques, 2011; Gao et al., 2013; Perry and Singh, 2014). Spatial beamformer analysis identified a set of regions of the occipitotemporal cortices as consistently responding differently to faces and objects. These included areas consistent with fMRI localizations of face areas based on contrasts showing a higher BOLD signal to faces over objects (Rossion et al., 2003; Grill-Spector et al., 2004; Winston et al., 2004; Fox et al., 2009; Rossion et al., 2012). Specifically, we identified a right lateralized fusiform gyrus source with a location consistent with fMRI studies reporting FFA (Goffaux et al., 2012; Slotnick and White, 2013) and sources in both the right and left lateral occipital cortices with a location consistent with fMRI studies reporting the occipital face area (OFA) (Arcurio et al., 2012; Goffaux et al., 2012; Slotnick and White, 2013). A further two regions were identified as showing consistent response differences between faces and objects that are not part of the established face-processing network: the occipital pole (MNI 33, −96, −7) and the left temporal pole (MNI −32, 9, −42).
Having identified brain locations that had temporally stable response differences to faces and objects, we tested specific hypotheses about adaptation profiles of the evoked response through generating VE time series estimates in source space. The left occipital pole VE showed a nonspecific pattern of adaptation to the adapted stimuli—that is, there was category-level adaptation of the M170 to both faces and objects and of the M250 to objects (with faces approaching significance) but no differential item-level adaptation to either category. Although the early latency of M170 adaptation effects (commencing ∼120 ms after stimulus) might seem surprising, this is not inconsistent with previous MEG studies reporting M170 as peaking earlier (e.g., ∼150 ms) than its EEG counterpart (Ewbank et al., 2008). Our ability to detect differences occurring before the peak amplitude may be because our analysis strategy was not constrained by a priori assumptions about component latencies. This pattern of adaptation is generally consistent with a role in the processing of both types of stimuli (which is unsurprising given that the coordinates are consistent with the location of early visual areas V2/V3 according to the Juelich Histological Atlas; Eickhoff et al., 2007). The observed pattern of signal attenuation could reflect either adaptation of neural populations encoding shared low-level visual features across stimuli within each separate category independently or across both categories. In either case, it is unsurprising that an early visual area should show a greater amplitude response to the sudden onset of a complex visual stimulus after a fixation screen than to the onset of such a stimulus after an already rich visual scene.
The fusiform gyrus VE showed a unique and intriguing pattern of adaptation consistent with a specific functional sensitivity to faces. That is, there was category-level adaptation of both the M170 and the M250 to faces and item-level adaptation of the M250 such that repeated presentations of the same identity faces lead to greater adaptation than to new identity faces. There was no adaptation to objects. This pattern of adaptation implies that the fusiform gyrus VE is engaged in specifically face-related processes at both M170 at M250 but that, whereas the operations performed at the later latency show sensitivity to invariant face features specific to the identity of the adaptor stimulus, those performed at the earlier latency do not. This is significant and important because it confirms and extends the standard neurocognitive model of the face-processing system as proposed by Haxby et al. (2000) and resolves a conflict between previous findings in the MEG/EEG and fMRI literature. fMRI studies have interrogated the functional sensitivity of this brain region by examining adaptation profiles to repeated presentations of faces. Such studies support the standard model, confirming a role for the FFA in the processing of invariant face features relating to identity (Winston et al., 2004; Davies-Thompson et al., 2009). The conflict with previous M/EEG literature arises because a number of studies have previously reported source analyses suggesting that there is an M/N170 generator in the fusiform area (Halgren et al., 2000; Deffke et al., 2007; Gao et al., 2013; Perry and Singh, 2014); however, the preponderance of research suggests that N170 is not sensitive to facial identity (Schweinberger, 2011). In fact, the dominant view with respect to the functional significance of the M/N170 is that it indexes the structural encoding of faces that precede processes relating to the computation of identity (Eimer, 2011). Therefore, there is a mismatch between the localization/functional sensitivity pairings as identified by different techniques. Our data resolve this because they imply that the fusiform gyrus is involved in the specific processing of faces at latencies consistent with both the M/N170 (because M170 amplitudes in this region adapt to faces but not objects) and the M/N250, but may only be engaged in identity related processes at this late latency (because M250 amplitudes in this region show greater adaptation to repeats of the same identity faces).
The left lateral occipital cortex VE showed category-level adaptation to faces at latencies consistent with both the M170 and the M250 components, but no adaptation to objects. This is consistent with a specific role in the processing of faces at both early and midlatencies, but not extending to the extraction of invariant face features. The location of this VE is reasonably consistent with the OFA identified by the Haxby model and the functional sensitivity and timing of evoked components in the current study are not incompatible with this model. Perhaps surprisingly though, the right lateral occipital cortex VE, which is also reasonably close to the right OFA (Arcurio et al., 2012; Goffaux et al., 2012), showed no specificity to faces in terms of the amplitudes of components of the evoked response despite the DSI analysis identifying consistent differences in responses to faces and objects in this region.
More broadly, our analyses suggest that components M1, M170, and M250 may have widely distributed generators across broad areas of the posterior brain. At present, it is unclear the extent to which the widespread spatial distribution of sources of the evoked components is veridical rather than an artifact of the smoothness of the beamformer's spatial filter. However, particular components have different functional sensitivities at disparate spatial locations and the pattern of these is not easily reconciled with an explanation based upon spatial smearing of the signal from unitary sources. We believe that this argues in favor of the major visual evoked components having widespread generators across the visual brain and that modulation of these components may reflect differential functional sensitivity in different cortical areas.
If this is so, it helps to resolve inconsistencies across previous M/EEG source localization studies that have variously reported fusiform gyrus (Linkenkaer-Hansen et al., 1998; Halgren et al., 2000; Mnatsakanian and Tarkka, 2004), STS (Itier et al., 2006), lateral occipital cortex (Schweinberger et al., 2002; Tanskanen et al., 2005), and lingual gyrus (Taylor et al., 2001; Gao et al., 2013) as being generators of the M/N170. In general, these studies have inverted sensor-space-evoked signals at particular latencies to particular stimuli (i.e., faces), but have been unable to explore differential patterns of functional sensitivity to different stimulus types in source space. Our analyses imply that the brain may indeed respond to faces, generating an M/N170 in all of these regions, but that it is only in a particular subset of these regions that this signal relates to processes that are particular to computations underlying the categorical perception of faces. More generally, our data imply that the early to midlatency components of the visually evoked brain response might be better conceptualized as representing the function of a widely dispersed generic carrier signal that is generated across large portions of the visual brain rather than representing a series of functionally separable and separately localizable operators.
In conclusion, using MEG, we have localized, with a high degree of spatial specificity, a network of brain regions that respond differentially to faces and objects that is consistent with expectations based upon previous fMRI literature. We have also explored the effects of stimulus repetition on the evoked brain response and shown differential functional sensitivity at key nodes of this network occurring at specific latencies. Most notably, we have shown that the right fusiform gyrus shows an adaptation profile consistent with a specific role in the processing of faces commencing at ∼130 ms after stimulus onset and continuing until ∼300 ms after stimulus onset, but with only the later portion of this response indexing processes that are sensitive to individual identity. We believe this to be an important advance with respect to our understanding of the spatiotemporal characteristics of the brain's face-processing network. Moreover, it is an important advance in the application of MEG, convincingly delivering upon MEG's promise to resolve brain signals in space and time simultaneously.
Footnotes
We thank Rebecca Millman for invaluable assistance in MEG data collection.
The authors declare no competing financial interests.
- Correspondence should be addressed to Patrick J. Johnston, Associate Professor, School of Psychology and Counseling, Queensland University of Technology, Victoria Park Road, Kelvin Grove, QLD 4059, Australia. patrick.johnston{at}qut.edu.au





{kind=link}
{kind=link}
{kind=link}
{kind=link}