



Abstract
Recognizing the voices of people we know does not only activate “voice areas” in the temporal lobe but also extraauditory areas including the fusiform “face area” (FFA). This cross-modal effect could reflect that individual face and voice information become specifically associated when becoming acquainted with a person. Here, we addressed whether the ability to have individual face representations 1) plays a role in voice recognition and 2) is required to observe cross-modal responses to voices in face areas. We compared speaker recognition performance and neuroimaging responses during the processing of familiar and nonfamiliar speakers' voices in a developmental prosopagnosic subject (SO) with the respective findings obtained in a group of 9 control subjects. Despite scoring worse than controls on recognition of familiar speakers' voices, SO had normal cross-modal responses in the FFA and normal connectivity between FFA and the voice regions. However, she had reduced activations in areas that usually respond to familiarity with people. An indication for the malfunctioning of her FFA was reduced connectivity of the FFA to a subset of these supramodal areas. In combination these data suggest that 1) voice recognition benefits from the ability to process faces at an individual level and 2) cross-modal association of voices and faces in the brain is achieved by a sensory binding and does not depend on a top–down mechanism subsequent to successful person recognition.
Introduction
Recognizing people is a multimodal and multifaceted process. In pathological conditions such as blindness or deafness, recognition can be accomplished by the sensory modalities that remain intact. If advanced processing stages for a single modality are impaired, as in prosopagnosia or phonagnosia, person identification is normally achieved by alternative features in the same modality, for example, biological motion patterns, or by other modalities. For instance, patients with prosopagnosia report relying on voices to identify people (Pallis 1955). In healthy subjects however, voice and face processing are not strictly separated but interact at the behavioral level. Recognition of a face is facilitated by previous exposure to the corresponding voice and vice versa (Ellis and others 1997; Schweinberger and others 1997), and voices that are presented along with the speaker's face are subsequently better remembered (Sheffert and Olson 2004). One possible neural account for voice–face interactions could be that voice and face modules in the brain are functionally connected. This is what our recent data suggested by showing that familiar speakers' voices activate the fusiform face area (FFA) (von Kriegstein and others 2005).
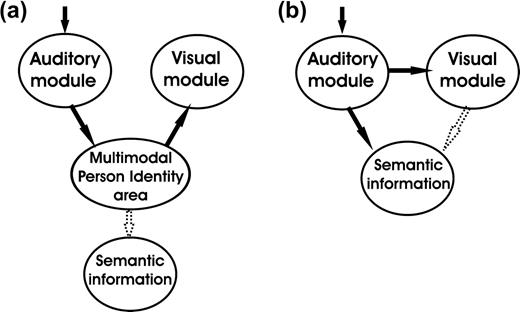
A mechanism by which familiar voices might recruit the FFA could be that once a speaker is recognized, this results in a top–down activation of the corresponding visual features of this individual that might be stored as templates in the FFA. In this case, however, activation of visual face regions would follow person identification and—as an epiphenomenon—would not contribute to voice recognition performance (Fig. 1a). In the framework of current models of multimodal person recognition, supramodal regions that are involved in identity processing could generate such an input to face-sensitive regions (Bruce and Young 1986; Burton and others 1990, 1999; Ellis and others 1997).
{kind=link}
Two alternative mechanisms of interaction of unisensory modules during recognition of familiar speakers' voices. If the visual module is activated through a top–down effect, its activation is unlikely to interfere with unimodal speaker recognition performance (a). If the visual module is activated through a low-level coupling, speaker/person recognition can already take place at the sensory level (b) and influence the level of activation in supramodal areas.
However, connectivity analysis in our recent functional magnetic resonance imaging (fMRI) study revealed that the variance in FFA activity during voice recognition was mostly accounted for by that of a voice-responsive area in the superior temporal sulcus (STS). This observation suggested a direct, low-level and automatic binding of voice–face information that is independent from person recognition on a multimodal level and possibly occurs before or in parallel with speaker identification. Such an early binding process could indeed contribute to accuracy and speed of recognition and reinforce activation in regions that are responsible for retrieving person-related semantic information (Fig. 1b).
In the present study, we sought to further clarify the mechanisms by which the FFA is cross-modally activated by voices and to understand how face processing interacts with voice recognition. We were particularly interested in studying whether impaired face recognition affects familiar voice recognition. We therefore contacted a developmentally prosopagnosic subject (SO) whose visual abilities had been previously investigated in depth by others. This subject suffers from an innate selective face recognition deficit whereas basic visual processing abilities are intact (Kress and Daum 2003). As SO was never able to recognize people from their faces, her condition differs from acquired prosopagnosia (Barton and Cherkasova 2003; Michelon and Biederman 2003) in that it covers perception and imagery of faces to the same extent (Nunn and others 2001). SO was previously described as having a marked deficit in face recognition (test: Recognition Memory Test (RMT)-faces; Warrington 1984) and famous versus nonfamous face discrimination (Kress and Daum 2003). SO can, however, judge faces as identical or different when they are presented at the same time (test: Tuebinger Affect Battery; Kress and Daum 2003). This ability is preserved in most developmental prosopagnosics, although they often show a significantly increased response time (Duchaine and Nakayama 2004). Furthermore SO's ability to judge and discriminate emotional expressions of faces, ability to reproduce complex figures, and her perception of objects and space are preserved (Kress and Daum 2003). SO claims to rely on extrafacial attributes such as gait and vocal features to identify people and reports that for her recognizing people heavily depends on the context in which she encounters them. Although they are not as severely affected as her, SO's parents share her difficulty to identify people from their faces, which underlines a genetic component in her syndrome (Grueter and others 2005).
In SO, we simultaneously measured fMRI activation and behavioral performance during recognition of familiar and nonfamiliar speakers voices and compared the data with those previously obtained in 9 healthy subjects (von Kriegstein and others 2005).
We assumed that, if the FFA is cross-modally activated by voices in a prosopagnosic subject, this would be an indication that a low-level binding takes place before person identity recognition. Furthermore, we were interested in the influence of the availability of face identity information on voice recognition performance. Normal subjects show a significant gain in familiar speaker voice recognition if corresponding faces have been concurrently encoded (Sheffert and Olson 2004). If recognition of familiar speakers' voices benefits from multisensory encoding, we predict that a prosopagnosic subject will be impaired on recognition of familiar speakers' voices.
Materials and Methods
Subjects
One prosopagnosic patient (SO, female, 35 years) and 9 right-handed control subjects (4 females, 5 males; 27–36 years) without audiological or neurological pathology participated in the study. Written informed consent was obtained from all participants in accordance with the requirements of the Ethics Committee of J.W. Goethe University, Frankfurt, Germany.
Stimulus Preparation and Delivery
Vocal stimuli were recorded (32 kHz sampling rate, 16 bit resolution), adjusted to the same overall sound pressure level, and processed using CoolEdit 2000 (Syntrillium Software, Scottsdale, AZ, USA) and Soundprobe (Hisoft Systems, Bedford, UK). Simple speech envelope noises (SENs) were derived from the vocal stimuli with a cutoff frequency of 2Hz using a Matlab (Mathworks, Sherborn, MA, USA) based program (Lorenzi and others 1999). All acoustic stimuli were presented binaurally to the subjects through a commercially available system (mr-confon, Magdeburg, Germany) and calibrated to produce an average signal-to-scanner noise ratio of 20 dB. Developmental prosopagnosics do not generally suffer from peripheral auditory deficits, and also SO does not have obvious peripheral hearing problems. We used similar levels of stimulation to test control subjects and SO.
Visual stimuli were frontal view pictures of familiar (colleagues/friends) and nonfamiliar faces, scrambled versions of the faces, and pictures of objects in canonical views. All stimuli were digital color photos with a size of 300 × 300 pixels.
Experimental Design
In the control group, we used 47 German sentences spoken by 14 nonfamiliar speakers (6 female/8 male) and 14 speakers who were personally known to all subjects (familiar voices: 5 female/9 male). We defined familiar speakers as personal acquaintances who are met on a daily basis. For SO, only 7 people were found who sufficiently met this criterion so that the same 47 sentences were recorded from these 7 acquaintances (familiar voices: all female) and 7 nonfamiliar persons (all female). Nonfamiliar speakers were not known to the participants before the experiment, neither by voice and face nor by name.
Prior to the experiment, subjects listened to all voices and sentences (each voice was presented 3 times saying different sentences) and to the SENs. They received an additional training on target nonfamiliar voices (12 sentences each) and target SENs (8 times each). This training was necessary to accustom the subjects to the presentation of familiar speakers' voices through the sound system. The additional training on nonfamiliar voices and SENs was used to obtain reasonably high recognition levels on these tasks. Stimuli were presented in 2 runs in blocks in a design described before in detail (see fig. 2 in von Kriegstein and others 2005). Blocks contained either sentences spoken by familiar speakers or by nonfamiliar speakers. Each block was preceded by the presentation of a target stimulus, that is, either a specific voice or a specific verbal content. Subjects had the task to press one button if it was the target stimulus and another if it was a nontarget. This resulted in 4 experimental conditions consisting in recognizing as a target: a specific voice in a block of familiar speakers' voices (fv), a nonfamiliar voice in a block of nonfamiliar speakers' voices (nv), a specific verbal content in a block of familiar speakers' voices (fc), and a specific verbal content in a block of nonfamiliar speakers' voices (nc). The experimental conditions were split into 3 blocks per condition presented in random order within and across conditions. Blocks with the auditory control condition (SENs) alternated with the experimental sentence/voice recognition conditions. Each block lasted 32 s and contained 8 items (sentences), of which 3 were targets. Each run lasted 22 min.
{kind=link}
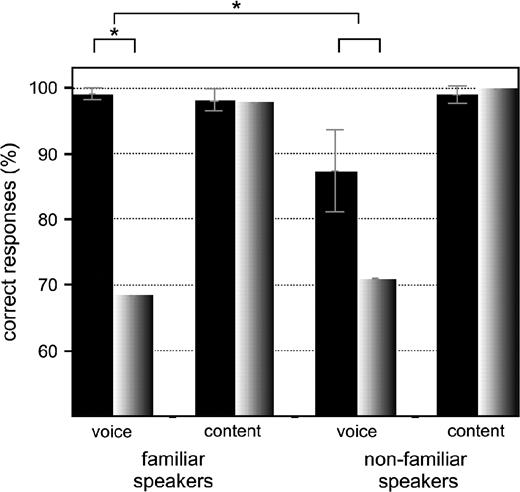
Behavioral results. The prosopagnosic subject SO (gray) is significantly impaired in voice recognition of familiar speakers' voices compared with a control group (black). Error bars present the 95% confidence interval of the mean.
Targets differed across blocks. Each target was presented 3 times before the ensuing block. A target voice spoke different sentences and vice versa; a target sentence was spoken by different voices, during the block and during target presentation. Therefore, the semantic content or the voice, respectively, could not be used as a cue to identify the targets. Subjects were requested to judge each item by pressing one button if it was a target and another if it was not.
SO and the controls were also studied in a visual face localizer study that comprised three 4.7-min fMRI runs. There were 4 stimulus conditions (objects, faces of familiar and faces of nonfamiliar people, and scrambled pictures) presented in blocks of 25.2 s. Single stimuli were presented every 720 ms (with the stimulus on for 525 ms and off for 195 ms). A fixation cross was introduced between the blocks for 16.8 s. The subjects' task was to passively look at the screen.
Protocol and Data Acquisition
Functional imaging was performed on a 1.5-T magnetic resonance scanner (Siemens Vision, Erlangen, Germany) with a standard head coil and gradient booster. We used echo-planar imaging to obtain blood oxygenation–sensitive image volumes with 24 oblique transverse slices every 2.7 s (voxel size 3.44 × 3.44 × 4 mm3, 1 mm gap, time to echo (TE) 60 ms) covering the whole brain. We acquired 494 volumes/run and 2 runs/subject (988 volumes/subject) for the auditory experiment and 105 volumes/run and 3 runs/subject (315 volumes/subject) in the visual face area localizer.
Data Processing
Statistical parametric mapping (SPM99/SPM2, http://www.fil.ion.ucl.ac.uk/spm/) was used to perform standard spatial preprocessing (realignment, normalization, and smoothing with a 10-mm Gaussian kernel for group analysis). Statistical parametric maps were generated by modeling the evoked hemodynamic response for the different stimuli as boxcars convolved with a synthetic hemodynamic response function in the context of the general linear model (Friston and others 1995). Population-level inferences concerning blood oxygen level dependent (BOLD) signal changes between conditions of interest were based on a random effects model that estimated the second-level t statistic at each voxel for the control group. We applied a threshold of P < 0.001, uncorrected, for hypothesis-related regions of interest and P < 0.05, corrected, for the rest of the brain volume. Statistical parametric maps for the control group and the prosopagnosic subject were compared using second-level statistics (2-sample t-test) with a voxelwise threshold of P < 0.001 and a 3-voxel minimum spatial extent threshold.
Region of interest (ROI) analyses of the FFA were performed using SPM2 and Marsbar-devel (http://marsbar.sourceforge.net/). For this single-subject analysis we used a Gaussian smoothing kernel of 4 mm. The ROI was derived from the contrast face > objects and comprised 14 voxels around the maximum at 50, −56, and −20.
We used the standard procedure in SPM2 (SPM2, http://www.fil.ion.ucl.ac.uk/spm/) for the analysis of psychophysiological interactions (PPIs) (Friston and others 1997). fMRI signal changes over time were extracted from a volume of interest with a radius of 5 mm centered on the response maximum for each single subject (for the right fusiform voice-responsive area) or for the nearest local maximum to the group maximum (for all familiarity responsive regions, that is, temporoparietal junction, medial parietal, anterior temporal) as representative time courses in terms of the first eigenvariate of the data. These mean corrected data (y) are multiplied with a condition-specific regressor (r) probing a familiarity effect (r = fv + fc + (nv × −1)+(nc × −1)) (fv = familiar speaker/voice recognition task; fc = familiar speaker/verbal content recognition task; nv = nonfamiliar speaker/voice recognition task; nc = nonfamiliar speaker/verbal content recognition task). The regressor ry for each region was used in separate analyses to test for PPIs, that is, voxels where the contribution of the sampled region changed significantly as a function of familiarity. In addition to ry, the design matrices also contained the regressors r and y as covariates of no interest (confounds). Design matrices were generated for each subject separately. A second-level 2-sample t-test was performed to assess differences in connectivity of the FFA and STS in SO in contrast to the controls. Responses were considered significant at P < 0.001 (uncorrected) if in accordance with prior hypotheses.
Questionnaire
To assess the identity cues by which SO usually recognizes her acquaintances, we asked her to describe the attributes she usually employs for recognition. We also enquired about specific aspects of the speakers' faces. Finally, to assess to which extent SO and the control group were able to imagine the faces of the personally familiar speakers, we asked them to describe these faces in as much detail as possible. The Appendix lists the questions and the answers given by SO.
Results
Behavioral Results
Despite the scanner noise, SO had perfect speech recognition for familiar (98% correct) and nonfamiliar voices (100% correct), as did controls in our experiments (98%/99%) and she achieved 87% for SENs (94% in controls, standard deviation [SD] 6.02). However, when tested in voice recognition tasks, her accuracy dropped to 69% for familiar speakers (99% in controls, SD 1.04) and 71% (86% in controls, SD 12.3) for nonfamiliar speakers (Fig. 2). In other words, SO's performance on voices of acquaintances dropped to the level that she displayed when confronted with voices of people she had never met before. Of note, we used the same acoustic material (3-s-long sentences) for voice recognition tasks as for verbal content tasks where she scored perfectly well. Her recognition of familiar speakers' voices lies clearly outside the normal range for the control, whereas her recognition score for nonfamiliar speakers' voices is only 1.2 SDs away from the mean. It is striking that SO lacked the familiarity benefit that we observed in the controls, who scored much better for voices of familiar speakers (fv > nv; paired sample t-test: t = 3.06, df 8, P < 0.01, 1-tailed). To test whether the difference between familiar and nonfamiliar speakers' voice recognition between SO and the control group is significant, we used the revised F statistics developed by Mycroft and others (2002) to compare a single subject with a control group. Using a repeated-measure analysis of variance we found a significant interaction between the voice recognition task and the group (F1,8 = 15.2, P < 0.006). According to the revised F statistics this effect of difference between SO and the control group during voice recognition is significant at P < 0.05 (Mycroft and others 2002). Post hoc testing confirmed that SO made significantly more errors than controls when recognizing voices of familiar speakers (nonparametric Mann–Whitney test: U = 0; W = 1; Z = −1.7; 1-tailed P < 0.04), whereas this is not the case for recognition of nonfamiliar speakers' voices (2-sample t-test: t = 1.1, df 8, 1-tailed P < 0.2). This latter fact together with the observation that SO performed at the level of controls for verbal recognition and SEN recognition underlines the fact that SO's deficit in processing familiar speakers' voices is unlikely to be based on any low-level auditory processing deficit. We observed no significant response time differences between SO and the control group in any condition.
Answers to the Questionnaire
SO reported recognizing people mostly by their belongings or attributes (car, dog, horse), their body shape (6 of the speakers), their voice/laugh (5 of the speakers), and their gait (4 of the speakers). She declared that she is unable to imagine faces. When asked to describe familiar speakers' faces in as much detail as possible, she could describe the haircut and hair color for all 7 of them but could not give consistent details about facial features such as eye color, shape of the nose, or skin texture. This contrasted to the control group where the subjects described faces in far more detail than SO (shape of face, shape of nose, thickness of lips, texture of skin, glasses). The Appendix lists the questions and the answers given by SO.
fMRI Face Area Localizer Activation in the Prosopagnosic Subject
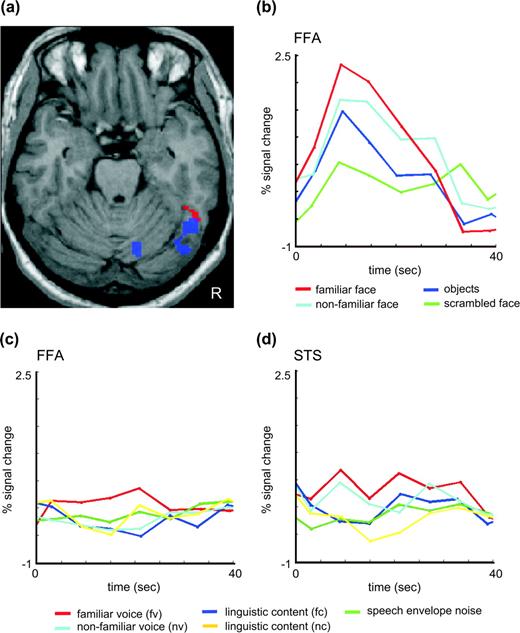
In our control group we had found activity in the FFA in the localizer faces > objects at a threshold of P < 0.001 uncorrected in all but 2 subjects (von Kriegstein and others 2005). SO showed only a subthreshold response to faces relative to objects in the right FFA (48, −57, −21, Z = 2.5, Fig. 3a, blue). Figure 3b shows the time courses for all visual conditions in this region. At a corrected threshold applied for the entire brain volume (P < 0.05) other responses to faces relative to objects occurred in the precuneus/retrosplenial area (−9, −48, 39) and bilateral angular gyri (−39, −66, 39; 48, −42, 39).
{kind=link}
Prosopagnosic subject SO. (a) Cross-modal activation of the FFA to familiar speakers' voices. Statistical parametric maps for the interaction between familiarity and task (red, fv > fc > uv > uc, P < 0.001, uncorrected) are overlaid with the localizer for the FFA (blue, face > object, this picture shows the contrast unfamiliar faces > scrambled faces at 0.05 corrected masked by faces > objects at 0.05 uncorrected for display purposes). (b)–(d) Time courses of the fMRI signal. (b) Time course obtained for the visual localizer scan in the FFA as localized by the contrast faces > objects. (c) Time course in the FFA in response to the auditory experiment. (d) Time course in the STS voice area in response to the auditory experiment.
fMRI Face Area Localizer: Differences between Prosopagnosic and Normal Subjects
The 2-sample t-tests indicated less activation (in terms of % signal change) in SO than in controls for face > objects (independent of familiarity) in the left fusiform area (−40,−50,−20; Z = 3.6; 3 voxels; Fig. 4b, blue; Table 1) and bilaterally in the temporal poles (Fig. 4a, blue; Table 1). The right FFA did not show a significant difference in signal change between SO and controls. This can be explained by the nonsignificant response to faces > objects in 2 of the control subjects (von Kriegstein and others 2005) together with nonsignificant but nevertheless subthreshold responses in SO in this region (as described earlier).
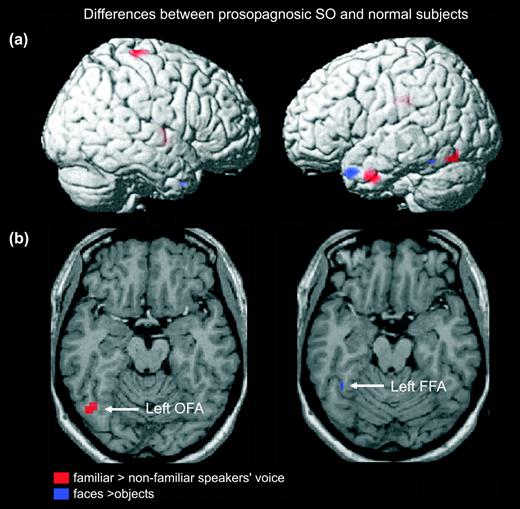
{kind=link}
Differences between normal subjects and the prosopagnosic subject SO in viewing faces and hearing familiar speakers. Red: activation lower in SO than in controls when recognizing familiar voices (familiar > nonfamiliar speakers' voices, P < 0.001 uncorrected; visualization with extent threshold 10 voxels). Blue: activation lower in SO than in controls when seeing faces (faces > objects, P < 0.001). (a) Rendering. (b) Overlay of activations on horizontal slices. OFA = occipital face area; FFA = fusiform face area.
Direct comparisons of activations between SO and controls
| Region | Prosopagnosic < normal subjects at P < 0.001 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Familiar speakers > nonfamiliar | Face > object | ||||||||||||||||||
| x | y | z | Z | CL | x | y | z | Z | CL | ||||||||||
| Temporal | |||||||||||||||||||
| Left | |||||||||||||||||||
| Temporal pole | −42 | 0 | −33 | 4.61 | 26 | −42 | 14 | −28 | 4.16 | 52 | |||||||||
| Posterior STG/TPJ | −42 | −45 | 9 | 3.31 | 5 | ||||||||||||||
| Fusiform | — | — | — | — | — | −40 | −50 | −20 | 2.63 | 3 | |||||||||
| Right | |||||||||||||||||||
| Temporal pole | — | — | — | — | — | 40 | 10 | −38 | 3.42 | 2 | |||||||||
| Occipital | |||||||||||||||||||
| Occipital inferior left | −48 | −69 | −18 | 4.05 | 10 | ||||||||||||||
| Parietal | |||||||||||||||||||
| Paracentral right | 27 | −30 | 69 | 4.63 | 15 | ||||||||||||||
| Midline | |||||||||||||||||||
| Cingulum middle | 21 | −12 | 39 | 4.58 | 6 | ||||||||||||||
| Cingulum middle/posterior | −6 | −30 | 27 | 4.42 | 24 | ||||||||||||||
| Mamilllary bodies | 0 | −9 | −15 | 3.61 | 7 | ||||||||||||||
| Frontal | |||||||||||||||||||
| SMA left | −18 | −9 | 60 | 4.25 | 6 | ||||||||||||||
| SMA right | 15 | −6 | 54 | 3.9 | 7 | ||||||||||||||
| Precentral right | 36 | −6 | 33 | 3.79 | 5 | ||||||||||||||
| 45 | −6 | 27 | 3.69 | 9 | |||||||||||||||
| Superior medial left | 0 | 63 | 27 | 3.65 | 8 | ||||||||||||||
| Basal ganglia | |||||||||||||||||||
| Right pallidum/putamen | 21 | −6 | −6 | 3.61 | 10 | ||||||||||||||
| Cerebellum | |||||||||||||||||||
| Right | 21 | −66 | −21 | 3.68 | 6 | ||||||||||||||
| Region | Prosopagnosic < normal subjects at P < 0.001 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Familiar speakers > nonfamiliar | Face > object | ||||||||||||||||||
| x | y | z | Z | CL | x | y | z | Z | CL | ||||||||||
| Temporal | |||||||||||||||||||
| Left | |||||||||||||||||||
| Temporal pole | −42 | 0 | −33 | 4.61 | 26 | −42 | 14 | −28 | 4.16 | 52 | |||||||||
| Posterior STG/TPJ | −42 | −45 | 9 | 3.31 | 5 | ||||||||||||||
| Fusiform | — | — | — | — | — | −40 | −50 | −20 | 2.63 | 3 | |||||||||
| Right | |||||||||||||||||||
| Temporal pole | — | — | — | — | — | 40 | 10 | −38 | 3.42 | 2 | |||||||||
| Occipital | |||||||||||||||||||
| Occipital inferior left | −48 | −69 | −18 | 4.05 | 10 | ||||||||||||||
| Parietal | |||||||||||||||||||
| Paracentral right | 27 | −30 | 69 | 4.63 | 15 | ||||||||||||||
| Midline | |||||||||||||||||||
| Cingulum middle | 21 | −12 | 39 | 4.58 | 6 | ||||||||||||||
| Cingulum middle/posterior | −6 | −30 | 27 | 4.42 | 24 | ||||||||||||||
| Mamilllary bodies | 0 | −9 | −15 | 3.61 | 7 | ||||||||||||||
| Frontal | |||||||||||||||||||
| SMA left | −18 | −9 | 60 | 4.25 | 6 | ||||||||||||||
| SMA right | 15 | −6 | 54 | 3.9 | 7 | ||||||||||||||
| Precentral right | 36 | −6 | 33 | 3.79 | 5 | ||||||||||||||
| 45 | −6 | 27 | 3.69 | 9 | |||||||||||||||
| Superior medial left | 0 | 63 | 27 | 3.65 | 8 | ||||||||||||||
| Basal ganglia | |||||||||||||||||||
| Right pallidum/putamen | 21 | −6 | −6 | 3.61 | 10 | ||||||||||||||
| Cerebellum | |||||||||||||||||||
| Right | 21 | −66 | −21 | 3.68 | 6 | ||||||||||||||
Note: This table shows local response maxima in the two-sample t-test comparing activation in the prosopagnosic subject SO to normal controls during the main effect of familiarity (fv + fc > nv + nc) (at P > 0.001 uncorrected, 5 voxel minimum) and face > object (at P < 0.001). CL refers to the number of voxels activated in the cluster. STG = superior temporal gyrus, TPJ = temporoparietal junction.
Direct comparisons of activations between SO and controls
| Region | Prosopagnosic < normal subjects at P < 0.001 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Familiar speakers > nonfamiliar | Face > object | ||||||||||||||||||
| x | y | z | Z | CL | x | y | z | Z | CL | ||||||||||
| Temporal | |||||||||||||||||||
| Left | |||||||||||||||||||
| Temporal pole | −42 | 0 | −33 | 4.61 | 26 | −42 | 14 | −28 | 4.16 | 52 | |||||||||
| Posterior STG/TPJ | −42 | −45 | 9 | 3.31 | 5 | ||||||||||||||
| Fusiform | — | — | — | — | — | −40 | −50 | −20 | 2.63 | 3 | |||||||||
| Right | |||||||||||||||||||
| Temporal pole | — | — | — | — | — | 40 | 10 | −38 | 3.42 | 2 | |||||||||
| Occipital | |||||||||||||||||||
| Occipital inferior left | −48 | −69 | −18 | 4.05 | 10 | ||||||||||||||
| Parietal | |||||||||||||||||||
| Paracentral right | 27 | −30 | 69 | 4.63 | 15 | ||||||||||||||
| Midline | |||||||||||||||||||
| Cingulum middle | 21 | −12 | 39 | 4.58 | 6 | ||||||||||||||
| Cingulum middle/posterior | −6 | −30 | 27 | 4.42 | 24 | ||||||||||||||
| Mamilllary bodies | 0 | −9 | −15 | 3.61 | 7 | ||||||||||||||
| Frontal | |||||||||||||||||||
| SMA left | −18 | −9 | 60 | 4.25 | 6 | ||||||||||||||
| SMA right | 15 | −6 | 54 | 3.9 | 7 | ||||||||||||||
| Precentral right | 36 | −6 | 33 | 3.79 | 5 | ||||||||||||||
| 45 | −6 | 27 | 3.69 | 9 | |||||||||||||||
| Superior medial left | 0 | 63 | 27 | 3.65 | 8 | ||||||||||||||
| Basal ganglia | |||||||||||||||||||
| Right pallidum/putamen | 21 | −6 | −6 | 3.61 | 10 | ||||||||||||||
| Cerebellum | |||||||||||||||||||
| Right | 21 | −66 | −21 | 3.68 | 6 | ||||||||||||||
| Region | Prosopagnosic < normal subjects at P < 0.001 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Familiar speakers > nonfamiliar | Face > object | ||||||||||||||||||
| x | y | z | Z | CL | x | y | z | Z | CL | ||||||||||
| Temporal | |||||||||||||||||||
| Left | |||||||||||||||||||
| Temporal pole | −42 | 0 | −33 | 4.61 | 26 | −42 | 14 | −28 | 4.16 | 52 | |||||||||
| Posterior STG/TPJ | −42 | −45 | 9 | 3.31 | 5 | ||||||||||||||
| Fusiform | — | — | — | — | — | −40 | −50 | −20 | 2.63 | 3 | |||||||||
| Right | |||||||||||||||||||
| Temporal pole | — | — | — | — | — | 40 | 10 | −38 | 3.42 | 2 | |||||||||
| Occipital | |||||||||||||||||||
| Occipital inferior left | −48 | −69 | −18 | 4.05 | 10 | ||||||||||||||
| Parietal | |||||||||||||||||||
| Paracentral right | 27 | −30 | 69 | 4.63 | 15 | ||||||||||||||
| Midline | |||||||||||||||||||
| Cingulum middle | 21 | −12 | 39 | 4.58 | 6 | ||||||||||||||
| Cingulum middle/posterior | −6 | −30 | 27 | 4.42 | 24 | ||||||||||||||
| Mamilllary bodies | 0 | −9 | −15 | 3.61 | 7 | ||||||||||||||
| Frontal | |||||||||||||||||||
| SMA left | −18 | −9 | 60 | 4.25 | 6 | ||||||||||||||
| SMA right | 15 | −6 | 54 | 3.9 | 7 | ||||||||||||||
| Precentral right | 36 | −6 | 33 | 3.79 | 5 | ||||||||||||||
| 45 | −6 | 27 | 3.69 | 9 | |||||||||||||||
| Superior medial left | 0 | 63 | 27 | 3.65 | 8 | ||||||||||||||
| Basal ganglia | |||||||||||||||||||
| Right pallidum/putamen | 21 | −6 | −6 | 3.61 | 10 | ||||||||||||||
| Cerebellum | |||||||||||||||||||
| Right | 21 | −66 | −21 | 3.68 | 6 | ||||||||||||||
Note: This table shows local response maxima in the two-sample t-test comparing activation in the prosopagnosic subject SO to normal controls during the main effect of familiarity (fv + fc > nv + nc) (at P > 0.001 uncorrected, 5 voxel minimum) and face > object (at P < 0.001). CL refers to the number of voxels activated in the cluster. STG = superior temporal gyrus, TPJ = temporoparietal junction.
fMRI Voice Recognition Activation in the Prosopagnosic Subject
For the main effect of familiarity (fv + fc > nv + nc) we did not find any regions that responded at a corrected threshold. At an uncorrected threshold, SO has activity in a subset of the regions also responding in this contrast in normal controls (von Kriegstein and others 2005), namely the left temporoparietal cortex and bilateral precuneus/retrosplenial area. Table 2 lists all activation for SO at P < 0.001, uncorrected. Previously we have shown FFA activation during recognition of familiar speakers' voices on a single-subject basis (von Kriegstein and others 2005). We also find this activity in SO: the right fusiform gyrus in SO responded significantly more to voices of familiar than nonfamiliar speakers during the voice recognition task (48, −57, −21; Z = 3.12; P < 0.001, uncorrected), and in the interaction of familiarity and task (fv > fs > nv > ns) (54, −50, −22; Z = 5.04, P < 0.001, Fig. 3a, red). Cross-modal activation of the FFA in voice recognition in SO was confirmed in a ROI analysis. Within the FFA as defined by faces > objects in the separate localizer study, the interaction (fv > fc > nv > nc) is significant (P < 0.04 corrected). The time course of activity for all conditions in the cross-modally activated FFA is depicted in Figure 3c. All activations are listed in Table 2 (P < 0.001 uncorrected).
Local activation maxima for the main effect of familiarity (fv + fc > nv + nc) and the interaction of familiarity and task (fv > fc > nv > nc) in the prosopagnosic subject
| Region | fv + fc > nv + nc | fv > fs > uv > uc | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | y | z | Z | CL | x | y | z | Z | CL | |||||||||
| Temporal | ||||||||||||||||||
| Fusiform right | 54 | −50 | −22 | 5.04 | 180 | |||||||||||||
| 52 | −44 | −14 | 4.05 | SCL | ||||||||||||||
| 40 | −34 | −20 | 4.03 | SCL | ||||||||||||||
| Occiptial | ||||||||||||||||||
| Lingual/occipital inferior right | 40 | −84 | −22 | 4.5 | 93 | |||||||||||||
| 30 | −78 | −24 | 3.12 | SCL | ||||||||||||||
| Superior occiptial left | −22 | −94 | 24 | 3.44 | 22 | |||||||||||||
| −4 | −86 | 46 | 3.31 | 9 | ||||||||||||||
| Parietal | ||||||||||||||||||
| Precuneus/cingulum | −6 | −50 | 46 | 4.26 | 143 | −14 | −50 | 38 | 3.69 | 37 | ||||||||
| −4 | −54 | 58 | 3.57 | SCL | ||||||||||||||
| Precuneus/retrosplenial | −12 | −64 | 12 | 3.56 | 42 | |||||||||||||
| Precuneus posterior | −8 | −74 | 60 | 5.48 | 110 | |||||||||||||
| Temporoparietal/angular right | 60 | −48 | 42 | 3.32 | 9 | |||||||||||||
| Temporoparietal/angular left | −40 | −62 | 16 | 3.44 | 10 | −48 | −64 | 40 | 3.57 | 16 | ||||||||
| Inferior left | −30 | −82 | 44 | 3.64 | 25 | |||||||||||||
| Frontal | ||||||||||||||||||
| Lateral | ||||||||||||||||||
| Inferior right | 60 | 32 | 4 | 5.39 | 90 | |||||||||||||
| Inferior left | −52 | 30 | 2 | 3.36 | 11 | |||||||||||||
| −52 | 20 | 4 | 3.25 | SCL | ||||||||||||||
| Middle right | 50 | 48 | 10 | 4.22 | 37 | |||||||||||||
| Middle left | −38 | 56 | 22 | 3.88 | 23 | |||||||||||||
| SMA left | −8 | 8 | 70 | 4.79 | 124 | |||||||||||||
| −22 | 6 | 68 | 3.95 | SCL | ||||||||||||||
| Orbital | ||||||||||||||||||
| Inferior orbital left | −28 | 40 | −22 | 4 | 23 | −48 | 42 | −18 | 3.68 | 10 | ||||||||
| Medial orbital right | 16 | 52 | −2 | 3.49 | 35 | |||||||||||||
| Superior orbital right | 10 | 60 | −20 | 3.48 | 9 | |||||||||||||
| Medial | ||||||||||||||||||
| Superior medial left | −6 | 64 | 32 | 3.53 | 9 | −12 | 64 | 16 | 3.93 | 62 | ||||||||
| −24 | 46 | 10 | 3.91 | 92 | ||||||||||||||
| −12 | 50 | 10 | 3.91 | SCL | ||||||||||||||
| Basal ganglia | ||||||||||||||||||
| Caudate/putamen | −14 | 20 | −4 | 5.53 | 971 | |||||||||||||
| −2 | 14 | −8 | 5.5 | SCL | ||||||||||||||
| Limbic | ||||||||||||||||||
| Subcallosal | −2 | 18 | −8 | 3.57 | 17 | −2 | 14 | −8 | 5.5 | SCL | ||||||||
| Cingulum anterior | −10 | 50 | 10 | 3.35 | 14 | |||||||||||||
| Cingulum middle | 4 | −14 | 46 | 3.4 | 13 | |||||||||||||
| −14 | 42 | 10 | 3.16 | SCL | ||||||||||||||
| Parahippocampal left | −32 | −42 | −4 | 3.7 | 40 | |||||||||||||
| −42 | −42 | −4 | 3.29 | SCL | ||||||||||||||
| Parahippocampal right | 34 | −44 | 0 | 4.12 | 56 | |||||||||||||
| Cerebellum | ||||||||||||||||||
| Right | 36 | −38 | −46 | 3.78 | 17 | |||||||||||||
| 2 | −64 | −38 | 3.54 | 10 | ||||||||||||||
| Region | fv + fc > nv + nc | fv > fs > uv > uc | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | y | z | Z | CL | x | y | z | Z | CL | |||||||||
| Temporal | ||||||||||||||||||
| Fusiform right | 54 | −50 | −22 | 5.04 | 180 | |||||||||||||
| 52 | −44 | −14 | 4.05 | SCL | ||||||||||||||
| 40 | −34 | −20 | 4.03 | SCL | ||||||||||||||
| Occiptial | ||||||||||||||||||
| Lingual/occipital inferior right | 40 | −84 | −22 | 4.5 | 93 | |||||||||||||
| 30 | −78 | −24 | 3.12 | SCL | ||||||||||||||
| Superior occiptial left | −22 | −94 | 24 | 3.44 | 22 | |||||||||||||
| −4 | −86 | 46 | 3.31 | 9 | ||||||||||||||
| Parietal | ||||||||||||||||||
| Precuneus/cingulum | −6 | −50 | 46 | 4.26 | 143 | −14 | −50 | 38 | 3.69 | 37 | ||||||||
| −4 | −54 | 58 | 3.57 | SCL | ||||||||||||||
| Precuneus/retrosplenial | −12 | −64 | 12 | 3.56 | 42 | |||||||||||||
| Precuneus posterior | −8 | −74 | 60 | 5.48 | 110 | |||||||||||||
| Temporoparietal/angular right | 60 | −48 | 42 | 3.32 | 9 | |||||||||||||
| Temporoparietal/angular left | −40 | −62 | 16 | 3.44 | 10 | −48 | −64 | 40 | 3.57 | 16 | ||||||||
| Inferior left | −30 | −82 | 44 | 3.64 | 25 | |||||||||||||
| Frontal | ||||||||||||||||||
| Lateral | ||||||||||||||||||
| Inferior right | 60 | 32 | 4 | 5.39 | 90 | |||||||||||||
| Inferior left | −52 | 30 | 2 | 3.36 | 11 | |||||||||||||
| −52 | 20 | 4 | 3.25 | SCL | ||||||||||||||
| Middle right | 50 | 48 | 10 | 4.22 | 37 | |||||||||||||
| Middle left | −38 | 56 | 22 | 3.88 | 23 | |||||||||||||
| SMA left | −8 | 8 | 70 | 4.79 | 124 | |||||||||||||
| −22 | 6 | 68 | 3.95 | SCL | ||||||||||||||
| Orbital | ||||||||||||||||||
| Inferior orbital left | −28 | 40 | −22 | 4 | 23 | −48 | 42 | −18 | 3.68 | 10 | ||||||||
| Medial orbital right | 16 | 52 | −2 | 3.49 | 35 | |||||||||||||
| Superior orbital right | 10 | 60 | −20 | 3.48 | 9 | |||||||||||||
| Medial | ||||||||||||||||||
| Superior medial left | −6 | 64 | 32 | 3.53 | 9 | −12 | 64 | 16 | 3.93 | 62 | ||||||||
| −24 | 46 | 10 | 3.91 | 92 | ||||||||||||||
| −12 | 50 | 10 | 3.91 | SCL | ||||||||||||||
| Basal ganglia | ||||||||||||||||||
| Caudate/putamen | −14 | 20 | −4 | 5.53 | 971 | |||||||||||||
| −2 | 14 | −8 | 5.5 | SCL | ||||||||||||||
| Limbic | ||||||||||||||||||
| Subcallosal | −2 | 18 | −8 | 3.57 | 17 | −2 | 14 | −8 | 5.5 | SCL | ||||||||
| Cingulum anterior | −10 | 50 | 10 | 3.35 | 14 | |||||||||||||
| Cingulum middle | 4 | −14 | 46 | 3.4 | 13 | |||||||||||||
| −14 | 42 | 10 | 3.16 | SCL | ||||||||||||||
| Parahippocampal left | −32 | −42 | −4 | 3.7 | 40 | |||||||||||||
| −42 | −42 | −4 | 3.29 | SCL | ||||||||||||||
| Parahippocampal right | 34 | −44 | 0 | 4.12 | 56 | |||||||||||||
| Cerebellum | ||||||||||||||||||
| Right | 36 | −38 | −46 | 3.78 | 17 | |||||||||||||
| 2 | −64 | −38 | 3.54 | 10 | ||||||||||||||
Note: Fv = voice recognition/familiar speaker; fc = verbal content recognition/familiar speaker; nv = voice recognition/nonfamiliar speaker; nc = verbal content recognition/nonfamiliar speaker. x, y, z are the Montreal Neurological Institute (MNI) coordinates of the local maxima (in millimeters). CL = refers to the number of voxels activated in the cluster. SCL = subcluster. Statistical threshold is P < 0.001 uncorrected, extend threshold 10 voxels.
Local activation maxima for the main effect of familiarity (fv + fc > nv + nc) and the interaction of familiarity and task (fv > fc > nv > nc) in the prosopagnosic subject
| Region | fv + fc > nv + nc | fv > fs > uv > uc | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | y | z | Z | CL | x | y | z | Z | CL | |||||||||
| Temporal | ||||||||||||||||||
| Fusiform right | 54 | −50 | −22 | 5.04 | 180 | |||||||||||||
| 52 | −44 | −14 | 4.05 | SCL | ||||||||||||||
| 40 | −34 | −20 | 4.03 | SCL | ||||||||||||||
| Occiptial | ||||||||||||||||||
| Lingual/occipital inferior right | 40 | −84 | −22 | 4.5 | 93 | |||||||||||||
| 30 | −78 | −24 | 3.12 | SCL | ||||||||||||||
| Superior occiptial left | −22 | −94 | 24 | 3.44 | 22 | |||||||||||||
| −4 | −86 | 46 | 3.31 | 9 | ||||||||||||||
| Parietal | ||||||||||||||||||
| Precuneus/cingulum | −6 | −50 | 46 | 4.26 | 143 | −14 | −50 | 38 | 3.69 | 37 | ||||||||
| −4 | −54 | 58 | 3.57 | SCL | ||||||||||||||
| Precuneus/retrosplenial | −12 | −64 | 12 | 3.56 | 42 | |||||||||||||
| Precuneus posterior | −8 | −74 | 60 | 5.48 | 110 | |||||||||||||
| Temporoparietal/angular right | 60 | −48 | 42 | 3.32 | 9 | |||||||||||||
| Temporoparietal/angular left | −40 | −62 | 16 | 3.44 | 10 | −48 | −64 | 40 | 3.57 | 16 | ||||||||
| Inferior left | −30 | −82 | 44 | 3.64 | 25 | |||||||||||||
| Frontal | ||||||||||||||||||
| Lateral | ||||||||||||||||||
| Inferior right | 60 | 32 | 4 | 5.39 | 90 | |||||||||||||
| Inferior left | −52 | 30 | 2 | 3.36 | 11 | |||||||||||||
| −52 | 20 | 4 | 3.25 | SCL | ||||||||||||||
| Middle right | 50 | 48 | 10 | 4.22 | 37 | |||||||||||||
| Middle left | −38 | 56 | 22 | 3.88 | 23 | |||||||||||||
| SMA left | −8 | 8 | 70 | 4.79 | 124 | |||||||||||||
| −22 | 6 | 68 | 3.95 | SCL | ||||||||||||||
| Orbital | ||||||||||||||||||
| Inferior orbital left | −28 | 40 | −22 | 4 | 23 | −48 | 42 | −18 | 3.68 | 10 | ||||||||
| Medial orbital right | 16 | 52 | −2 | 3.49 | 35 | |||||||||||||
| Superior orbital right | 10 | 60 | −20 | 3.48 | 9 | |||||||||||||
| Medial | ||||||||||||||||||
| Superior medial left | −6 | 64 | 32 | 3.53 | 9 | −12 | 64 | 16 | 3.93 | 62 | ||||||||
| −24 | 46 | 10 | 3.91 | 92 | ||||||||||||||
| −12 | 50 | 10 | 3.91 | SCL | ||||||||||||||
| Basal ganglia | ||||||||||||||||||
| Caudate/putamen | −14 | 20 | −4 | 5.53 | 971 | |||||||||||||
| −2 | 14 | −8 | 5.5 | SCL | ||||||||||||||
| Limbic | ||||||||||||||||||
| Subcallosal | −2 | 18 | −8 | 3.57 | 17 | −2 | 14 | −8 | 5.5 | SCL | ||||||||
| Cingulum anterior | −10 | 50 | 10 | 3.35 | 14 | |||||||||||||
| Cingulum middle | 4 | −14 | 46 | 3.4 | 13 | |||||||||||||
| −14 | 42 | 10 | 3.16 | SCL | ||||||||||||||
| Parahippocampal left | −32 | −42 | −4 | 3.7 | 40 | |||||||||||||
| −42 | −42 | −4 | 3.29 | SCL | ||||||||||||||
| Parahippocampal right | 34 | −44 | 0 | 4.12 | 56 | |||||||||||||
| Cerebellum | ||||||||||||||||||
| Right | 36 | −38 | −46 | 3.78 | 17 | |||||||||||||
| 2 | −64 | −38 | 3.54 | 10 | ||||||||||||||
| Region | fv + fc > nv + nc | fv > fs > uv > uc | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | y | z | Z | CL | x | y | z | Z | CL | |||||||||
| Temporal | ||||||||||||||||||
| Fusiform right | 54 | −50 | −22 | 5.04 | 180 | |||||||||||||
| 52 | −44 | −14 | 4.05 | SCL | ||||||||||||||
| 40 | −34 | −20 | 4.03 | SCL | ||||||||||||||
| Occiptial | ||||||||||||||||||
| Lingual/occipital inferior right | 40 | −84 | −22 | 4.5 | 93 | |||||||||||||
| 30 | −78 | −24 | 3.12 | SCL | ||||||||||||||
| Superior occiptial left | −22 | −94 | 24 | 3.44 | 22 | |||||||||||||
| −4 | −86 | 46 | 3.31 | 9 | ||||||||||||||
| Parietal | ||||||||||||||||||
| Precuneus/cingulum | −6 | −50 | 46 | 4.26 | 143 | −14 | −50 | 38 | 3.69 | 37 | ||||||||
| −4 | −54 | 58 | 3.57 | SCL | ||||||||||||||
| Precuneus/retrosplenial | −12 | −64 | 12 | 3.56 | 42 | |||||||||||||
| Precuneus posterior | −8 | −74 | 60 | 5.48 | 110 | |||||||||||||
| Temporoparietal/angular right | 60 | −48 | 42 | 3.32 | 9 | |||||||||||||
| Temporoparietal/angular left | −40 | −62 | 16 | 3.44 | 10 | −48 | −64 | 40 | 3.57 | 16 | ||||||||
| Inferior left | −30 | −82 | 44 | 3.64 | 25 | |||||||||||||
| Frontal | ||||||||||||||||||
| Lateral | ||||||||||||||||||
| Inferior right | 60 | 32 | 4 | 5.39 | 90 | |||||||||||||
| Inferior left | −52 | 30 | 2 | 3.36 | 11 | |||||||||||||
| −52 | 20 | 4 | 3.25 | SCL | ||||||||||||||
| Middle right | 50 | 48 | 10 | 4.22 | 37 | |||||||||||||
| Middle left | −38 | 56 | 22 | 3.88 | 23 | |||||||||||||
| SMA left | −8 | 8 | 70 | 4.79 | 124 | |||||||||||||
| −22 | 6 | 68 | 3.95 | SCL | ||||||||||||||
| Orbital | ||||||||||||||||||
| Inferior orbital left | −28 | 40 | −22 | 4 | 23 | −48 | 42 | −18 | 3.68 | 10 | ||||||||
| Medial orbital right | 16 | 52 | −2 | 3.49 | 35 | |||||||||||||
| Superior orbital right | 10 | 60 | −20 | 3.48 | 9 | |||||||||||||
| Medial | ||||||||||||||||||
| Superior medial left | −6 | 64 | 32 | 3.53 | 9 | −12 | 64 | 16 | 3.93 | 62 | ||||||||
| −24 | 46 | 10 | 3.91 | 92 | ||||||||||||||
| −12 | 50 | 10 | 3.91 | SCL | ||||||||||||||
| Basal ganglia | ||||||||||||||||||
| Caudate/putamen | −14 | 20 | −4 | 5.53 | 971 | |||||||||||||
| −2 | 14 | −8 | 5.5 | SCL | ||||||||||||||
| Limbic | ||||||||||||||||||
| Subcallosal | −2 | 18 | −8 | 3.57 | 17 | −2 | 14 | −8 | 5.5 | SCL | ||||||||
| Cingulum anterior | −10 | 50 | 10 | 3.35 | 14 | |||||||||||||
| Cingulum middle | 4 | −14 | 46 | 3.4 | 13 | |||||||||||||
| −14 | 42 | 10 | 3.16 | SCL | ||||||||||||||
| Parahippocampal left | −32 | −42 | −4 | 3.7 | 40 | |||||||||||||
| −42 | −42 | −4 | 3.29 | SCL | ||||||||||||||
| Parahippocampal right | 34 | −44 | 0 | 4.12 | 56 | |||||||||||||
| Cerebellum | ||||||||||||||||||
| Right | 36 | −38 | −46 | 3.78 | 17 | |||||||||||||
| 2 | −64 | −38 | 3.54 | 10 | ||||||||||||||
Note: Fv = voice recognition/familiar speaker; fc = verbal content recognition/familiar speaker; nv = voice recognition/nonfamiliar speaker; nc = verbal content recognition/nonfamiliar speaker. x, y, z are the Montreal Neurological Institute (MNI) coordinates of the local maxima (in millimeters). CL = refers to the number of voxels activated in the cluster. SCL = subcluster. Statistical threshold is P < 0.001 uncorrected, extend threshold 10 voxels.
fMRI Voice Recognition: Differences between Prosopagnosic and Normal Subjects
To determine neural response differences between controls and SO, we performed 2-sample t-tests on the individual statistical parametric maps (Table 1 and Fig. 4a,b). When comparing responses to voices of acquaintances with those to voices that were heard for the first time during the experiment (independent of task), we observed that several regions were less active (P < 0.001 uncorrected) in SO than in controls (Table 1). These regions included brain structures that are known to respond to familiar stimuli (left temporoparietal junction, left anterior temporal region, posterior cingulum/retrosplenial cortex) as well as the left occipital face area (−48, −69, −18; 10 voxels) but not the FFA. We did not observe differential FFA activation between SO and the control subjects, neither in the contrast of familiar versus nonfamiliar speakers' voice recognition (fv > uv) nor in the interaction of familiarity and task (fv > fc > nv > nc).
fMRI Voice Recognition Analyses of Connectivity (PPI) in the Prosopagnosic Subject
Condition-specific (fv + fc > uv + uc) functional connectivity analyses of SO are summarized in Table 3. Under conditions with familiar speakers' voices, the cross-modally activated fusiform area showed enhanced connectivity only with the STS voice region but with none of the supramodal familiarity areas. The STS, in contrast, was functionally connected to all the supramodal familiarity regions showing a significant response in SO.
Analyses of condition-specific (familiar speakers; fv + fs > uv + us) functional connectivity in SO
| Sampled region | Target region | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Right STS | Right fusiform | Medial parietal | Right temporoparietal | Left temporoparietal | Right anterior temporal | |||||||
| Right STS | 63, −3, −9 | — | 54, −54, −26a | 4, −44, 18 | 60, −66, 22 | ns | ns | |||||
| Right fusiform | 54, −50, −22 | 66, −2, −14 | — | ns | ns | ns | ns | |||||
| Medial parietal | 6, −57, 21 | 66, −4, −10 | ns | — | 42, −60, 16 | −46, −60, 8 | 60, 10, −20 | |||||
| Right temporoparietal | 54, −60, 18 | 66, −4, −10 | ns | ns | — | ns | ns | |||||
| Left temporoparietal | −40, −62, 16 | 66, −4, −6 | ns | ns | 42, −58, 16 | — | ns | |||||
| Right anterior temporal | 60, −3, −30 | 66, −4, −12 | ns | ns | ns | ns | — | |||||
| Left anterior temporal | — | — | — | — | — | — | — | |||||
| Sampled region | Target region | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Right STS | Right fusiform | Medial parietal | Right temporoparietal | Left temporoparietal | Right anterior temporal | |||||||
| Right STS | 63, −3, −9 | — | 54, −54, −26a | 4, −44, 18 | 60, −66, 22 | ns | ns | |||||
| Right fusiform | 54, −50, −22 | 66, −2, −14 | — | ns | ns | ns | ns | |||||
| Medial parietal | 6, −57, 21 | 66, −4, −10 | ns | — | 42, −60, 16 | −46, −60, 8 | 60, 10, −20 | |||||
| Right temporoparietal | 54, −60, 18 | 66, −4, −10 | ns | ns | — | ns | ns | |||||
| Left temporoparietal | −40, −62, 16 | 66, −4, −6 | ns | ns | 42, −58, 16 | — | ns | |||||
| Right anterior temporal | 60, −3, −30 | 66, −4, −12 | ns | ns | ns | ns | — | |||||
| Left anterior temporal | — | — | — | — | — | — | — | |||||
Note: Sampled and target regions are derived from the previously reported analysis of the control group (von Kriegstein and others 2005). ns = not significant. The statistical threshold is P < 0.001, uncorrected. Numbers present the coordinates (x, y, z) of the local maxima (in millimeters). Target regions are located as the nearest local maxima to the sampled region.
This corresponds to the nearest suprathreshold voxel, the nearest local maximum for the FFA is 56, −62, and −22.
Analyses of condition-specific (familiar speakers; fv + fs > uv + us) functional connectivity in SO
| Sampled region | Target region | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Right STS | Right fusiform | Medial parietal | Right temporoparietal | Left temporoparietal | Right anterior temporal | |||||||
| Right STS | 63, −3, −9 | — | 54, −54, −26a | 4, −44, 18 | 60, −66, 22 | ns | ns | |||||
| Right fusiform | 54, −50, −22 | 66, −2, −14 | — | ns | ns | ns | ns | |||||
| Medial parietal | 6, −57, 21 | 66, −4, −10 | ns | — | 42, −60, 16 | −46, −60, 8 | 60, 10, −20 | |||||
| Right temporoparietal | 54, −60, 18 | 66, −4, −10 | ns | ns | — | ns | ns | |||||
| Left temporoparietal | −40, −62, 16 | 66, −4, −6 | ns | ns | 42, −58, 16 | — | ns | |||||
| Right anterior temporal | 60, −3, −30 | 66, −4, −12 | ns | ns | ns | ns | — | |||||
| Left anterior temporal | — | — | — | — | — | — | — | |||||
| Sampled region | Target region | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Right STS | Right fusiform | Medial parietal | Right temporoparietal | Left temporoparietal | Right anterior temporal | |||||||
| Right STS | 63, −3, −9 | — | 54, −54, −26a | 4, −44, 18 | 60, −66, 22 | ns | ns | |||||
| Right fusiform | 54, −50, −22 | 66, −2, −14 | — | ns | ns | ns | ns | |||||
| Medial parietal | 6, −57, 21 | 66, −4, −10 | ns | — | 42, −60, 16 | −46, −60, 8 | 60, 10, −20 | |||||
| Right temporoparietal | 54, −60, 18 | 66, −4, −10 | ns | ns | — | ns | ns | |||||
| Left temporoparietal | −40, −62, 16 | 66, −4, −6 | ns | ns | 42, −58, 16 | — | ns | |||||
| Right anterior temporal | 60, −3, −30 | 66, −4, −12 | ns | ns | ns | ns | — | |||||
| Left anterior temporal | — | — | — | — | — | — | — | |||||
Note: Sampled and target regions are derived from the previously reported analysis of the control group (von Kriegstein and others 2005). ns = not significant. The statistical threshold is P < 0.001, uncorrected. Numbers present the coordinates (x, y, z) of the local maxima (in millimeters). Target regions are located as the nearest local maxima to the sampled region.
This corresponds to the nearest suprathreshold voxel, the nearest local maximum for the FFA is 56, −62, and −22.
fMRI Voice Recognition Analyses of Connectivity in the Prosopagnosic Subject: Differences between Prosopagnosic and Normal Subjects
Comparison of results for condition-specific (fv + fc > uv + uc) functional connectivity of the FFA in SO and the controls revealed as hypothesized that the FFA interacts less with supramodal familiarity areas, that is, the left temporoparietal junction (−42, −54, 26; Z = 3.93; CL 48; P < 0.001) and an area in left anterior temporal lobe (−34 −2 −38; Z = 3; CL 7; P < 0.001). Connectivity between FFA and STS is not reduced in SO, neither when sampling from the FFA nor from the STS. The time courses of activity in SO's STS voice region is shown in Figure 3d.
Discussion
Previous models of person recognition assume that multimodal information is bound together by a supramodal level that responds to any attribute of a person independent of modality. Only after passing through that level, cross-modal association from voice-to-face information could be made (Fig. 1a). Previous behavioral studies (Ellis and others 1997; Schweinberger and others 1997) and imaging data (von Kriegstein and others 2005), however, suggest an early binding of face and voice information preceding the supramodal stage (Fig. 1b). The current results further support a low-level binding of person-specific auditory–visual sensory information.
Voice-to-Face Cross-Modal Responses in SO
Our former study demonstrated recruitment of the FFA during tasks involving familiar speaker recognition (von Kriegstein and others 2005). As the effect was not observed for recognition of nonfamiliar speakers, we hypothesized that cross-modal FFA activation depends on previous familiarization with the speaker during which the specific individual face and voice information become associated. As prosopagnosic subjects do not process faces on an individual basis, it is interesting to observe that cross-modal FFA responses to familiar compared with nonfamiliar speakers' voices persisted in SO. Cross-modal responses in the visual cortex in the absence of a visual stimulus may be thought of as reflecting visual imagery (Sathian and Zangaladze 2002; for discussion see Amedi and others 2005). Our results here, however, provide a strong argument in favor of the view that it does not necessarily imply a precise visual representation of an individual face triggered by person recognition. Despite a weak response to faces compared with objects in the right FFA, that region's responses to familiar speakers' voices in SO did not differ in terms of activity from those observed in the control group. Furthermore, the connectivity between the FFA and the STS voice regions did not differ in SO in comparison with control subjects. This suggests that coupling between voice and face regions is made before person identity coding and already exists at a sensory level. In contrast to the preserved FFA response and connectivity to STS voice–responsive areas, multimodal areas that are commonly activated by exposure to familiar stimuli (anterior temporal region, posterior cingulate/retrosplenial cortex, temporoparietal junction) showed significantly less activity in SO than in the controls (Gorno-Tempini and others 1998; Nakamura and others 2000; Shah and others 2001; Rotshtein and others 2005; von Kriegstein and others 2005). These multimodal areas are involved in person recognition, and their reduced responses might hence be the result of the fact that SO was not able to recognize familiar voices as accurately as controls. Moreover, our fMRI results denote that the right fusiform responses to familiar speakers' voices did not critically depend on concomitant activation in supramodal regions that respond to the identity of familiar speakers. Had this been the case, we would have expected that reduced activation in supramodal areas would also have propagated to the FFA and resulted in less activation there. Furthermore, we found less functional connectivity between the FFA and these supramodal areas in SO compared with the controls. These observations therefore support the view that FFA responses to voices correspond to a sensory binding that occurs before voice recognition.
Whether auditory and visual modalities interact prior to or beyond a multimodal person recognition stage has important implications for functional models of unimodal recognition. As illustrated in Figure 1b, if activity in face-specific neuronal ensembles in response to a heard voice arises from an early coupling between voice and face sensory modules, then this coupling might affect recognition performance. Alternatively, if FFA activation results from a top–down effect triggered by supramodal areas that subserve person recognition (Fig. 1a), then voice–face interaction should not have an impact on speaker recognition performance. Measuring voice recognition scores in a prosopagnosic patient critically addresses this question.
Impairment of Face Processing Interferes with Voice Recognition
In contrast with her claim to compensate her deficit by resorting to voice recognition, SO did not score better than controls in familiar speakers' voice recognition tests. Although she scored above chance level, recognition of familiar speakers' voices in SO was even significantly reduced relative to controls (69% correct responses in SO, 99% in controls). Remarkably, unlike controls, she showed no advantage for voices of her acquaintances compared with voices of persons she had never encountered before.
As SO was not impaired (across familiar and nonfamiliar voices) when judging the verbal content of sentences, her deficit in familiar speakers' voice recognition is unlikely to be related to a more general auditory processing deficit. Accordingly, there was also no deficit in activation of SO's voice regions in the superior temporal cortex compared with the controls.
Overall, SO was impaired in the situation where controls could use experience-based cross-modal binding whereas she could not. This impairment is remarkable because one would have expected that SO, who could never develop individual face representations, would have elaborated other compensatory strategies since very early on in her life. Sporadic reports in the literature converge with our findings. In the few prosopagnosic cases in whom voice recognition has been investigated, the face recognition deficit was accompanied by some deficit in recognition of famous voices (Van Lancker and Canter 1982; Hanley and others 1989; Neuner and Schweinberger 2000). Our data also agree with prior behavioral studies that suggest that coupling voice and face information might actually serve to enhance voice recognition performance (Sheffert and Olson 2004). Furthermore, such functional association would confirm the principles that have emerged from former findings where the impact of audio–visual coupling was shown to enhance performance even within a single modality and not only in tasks with multimodal input (Giraud and others 2001).
Potential Functional Relevance of Cross-Modal FFA Activation
The current fMRI and behavioral observations in a single patient, however, do not permit us to conclude that the physiological voice–face cross-modal effect described previously (von Kriegstein and others 2005) is a neural signature of the improvement of voice recognition by multisensory encoding (Sheffert and Olson 2004). Normal cross-modal responses to voices in SO's FFA and normal connectivity between her FFA and STS indicate that her problem in familiar speaker recognition does not arise from an alteration in the low-level binding between auditory and visual association cortices. Her deficit in familiar speakers' voice recognition might arise, however, from an altered function of this region (Schiltz and others 2005), leading to less connectivity to higher level cortical areas. SO had subthreshold responses in the right FFA in response to faces (faces > objects) and significantly reduced responses in the left FFA compared with controls. This observation, however, does not suffice to establish altered function in the FFA region. Although numerous studies specify that this region plays a critical role in face detection and identification (Grill-Spector and others 2004), famous face processing (George and others 1999), and perception of face uniqueness (Eger and others 2004), some prosopagnosics may have normal FFA activation (Hasson and others 2003; Rossion and others 2003; although not all, see Hadjikhani and de Gelder 2002), whereas subjects with intact face recognition may respond weakly (Kanwisher and others 1997). Rather than concluding that the FFA function could be perfectly normal in a prosopagnosic subject as SO, a more reasonable view would be that contrasting activity in response to faces versus objects is not an appropriate experimental way of establishing abnormal function, as suggested by the recent observation that prosopagnosic patients can have abnormal responses in the FFA to individual faces only (Schiltz and others 2005). Less functional connectivity between SO's FFA and supramodal familiarity regions, that is, left temporoparietal junction and anterior temporal lobe, could be an indication for a malfunction of the FFA.
We suggest that the coupling at a sensory level between STS and FFA is necessary but not sufficient for optimal speaker recognition. The optimal recognition of familiar speakers' voices most likely depends on the functional integrity of the FFA or rather of neural subpopulations embedded in the fusiform region.
Conclusions
By comparing functional imaging data between the developmental prosopagnosic SO and control subjects we confirm that the activation of face areas by voices results from direct functional interaction between the STS voice area and the FFA (von Kriegstein and others 2005). As familiar speaker recognition was selectively impaired in SO, we further propose that the coupling between voice and face sensory modules occurs at a processing level that is low enough to influence voice and person recognition.
However, the fact that functional STS–FFA coupling is preserved despite a behavioral deficit in familiar speakers' voice recognition in SO suggests that FFA activation by voices does not suffice to determine voice–face behavioral interactions in normal subjects. As the functionality of the FFA is altered in SO, we can nonetheless propose that the cooperativity between the STS and FFA is necessary for correct voice recognition; the ease, however, with which familiar speakers are recognized additionally depends on the integrity of the face area.
Appendix
Questionnaire
Please describe as detailed as possible the face of the following people (A, B, C, D, E, F, G).
A: middle-long straight red-blond hair.
B: puts on make-up, blond long, a little bit curled hair.
C: black curly hair, her face is not as uniform as the others but I do not know why.
D: blond, in the moment rather shorter hair, laughs a lot.
E: brown middle-long hair, sometimes gray hair line, a more narrow face than D (E.'s sister).
F: blond.
G: has white hair, is older.
How would you recognize A, B, C, D, E, F, G in a familiar surrounding (e.g., the riding stable where the speakers usually meet)?
A: her dog, her horse, her movement (often the shoulders are a bit bent), her voice, her car, slender figure.
B: often aggressive voice, her horse, normal figure.
C: her curly hair; her behavior, her laugh, her dog, not tall, athletic/sturdy body.
D: I usually do not recognize her, her voice, her typical laugh, in the meanwhile she has twins, so I recognize her by that or by her horse, sturdy and small figure.
E: I recognize her better than D, usually by her horse, but also by her figure and movement, her hair (although for my taste it changes too often).
F: her horse, the way of greeting me, her voice, the way she moves, normal-sturdy figure, is pregnant at the moment.
G: is the oldest in the stable, walks a little bit bent and is recognizable by her movement.
Which eye color have A, B, C, D, E, F, G?
A: brown.
B: ?
C: green (but I only know it because she told me, I would have guessed that she has brown eyes).
D: ?
E: ?
F: blue?
G: brown?
Who has the snubbiest nose?
…according to the type of person I would say D (she has this typical cheeky character of snub-nosed people …).
Who is wearing glasses?
C sometimes, A not (I know these two very well so that's why I know it). For the others I do not know, nobody I would say, probably G because she is the oldest one.
Who has the most freckles?
…often red-haired and blond people have freckles, B uses too much make-up, so one would probably not see it, A does not have any, I know that. I do not know the original hair color of G, so I am not sure whether it is A, B, or G.
We would like to thank SO very much for her participation in this study. KVK and AK are funded by the Volkswagenstiftung and ALG by the German Federal Ministry of Education and Research (BMBF) (Germany). The sound delivery system was acquired from a BMBF grant.
References
Amedi A, von Kriegstein K, van Atteveldt NM, Beauchamp MS, Naumer MJ.
Barton JJ, Cherkasova M.
Burton AM, Bruce V, Hancock PJB.
Burton AM, Bruce V, Johnston RA.
Duchaine BC, Nakayama K.
Eger E, Schyns PG, Kleinschmidt A.
Ellis HD, Jones DM, Mosdell N.
Friston KJ, Buechel C, Fink GR, Morris J, Rolls E, Dolan RJ.
Friston KJ, Holmes AP, Worsley KJ, Poline JP, Frith CD, Frackowiak RSJ.
George N, Dolan RJ, Fink GR, Baylis GC, Russell C, Driver J.
Giraud AL, Price CJ, Graham JM, Truy E, Frackowiak RS.
Gorno-Tempini ML, Price CJ, Josephs O, Vandenberghe R, Cappa SF, Kapur N, Frackowiak RS, Tempini ML.
Grill-Spector K, Knouf N, Kanwisher N.
Grueter M, Grueter T, Bell V, Horst J, Laskowski W, Sperling K, Halligan PW, Ellis HD, Kennerknecht I.
Hadjikhani N, de Gelder B.
Hanley JR, Young AW, Pearson NA.
Hasson U, Avidan G, Deouell LY, Bentin S, Malach R.
Kanwisher N, McDermott J, Chun MM.
Kress T, Daum I.
Lorenzi C, Berthommier F, Apoux F, Bacri N.
Michelon P, Biederman I.
Mycroft RH, Mitchell DC, Kay J.
Nakamura K, Kawashima R, Sato N, Nakamura A, Sugiura M, Kato T, Hatano K, Ito K, Fukuda H, Schormann T, Zilles K.
Neuner F, Schweinberger SR.
Nunn JA, Postma P, Pearson R.
Pallis CA.
Rossion B, Caldara R, Seghier M, Schuller AM, Lazeyras F, Mayer E.
Rotshtein P, Henson RN, Treves A, Driver J, Dolan RJ.
Sathian K, Zangaladze A.
Schiltz C, Sorger B, Caldara R, Ahmed F, Mayer E, Goebel R, Rossion B. July 20,
Schweinberger SR, Herholz A, Stief V.
Shah NJ, Marshall JC, Zafiris O, Schwab A, Zilles K, Markowitsch HJ, Fink GR.
Sheffert SM, Olson E.
Van Lancker DR, Canter JG.
von Kriegstein K, Kleinschmidt A, Sterzer P, Giraud AL.
Author notes
1Cognitive Neurology Unit, Department of Neurology, J.W. Goethe University, Frankfurt am Main, Germany, 2Wellcome Department of Imaging Neuroscience, University College London, 12 Queen Square, London WC1N 3BG, UK and 3Laboratoire de Neurosciences Cognitives, Département d'Études Cognitives, Ecole Normale Supérieure, Paris, France